as a Challenge for Computer Science and Linguistics
| see L&T'05 photogallery |
as a Challenge for Computer Science and Linguistics |






|
|
Dear Colleagues, You are kindly invited to participate in L&T'05, a conference organized by the Faculty of Mathematics and Computer Science of Adam Mickiewicz University, Poznań, Poland in cooperation with Adam Mickiewicz University Foundation. This will be held in parallel to Infosystem Forum 2005 (April 19-21, 2005) and the 36th Poznań Linguistic Meeting (April 22-24, 2005).
The increasing importance of human language technologies is a challenge for both the computer science and linguistics communities as these technologies become an ever more essential element of our everyday technological environment. Since Ajdukiewicz, Tarski, Turing and Chomsky (i.e. since the very beginning of the Computer Age) these fields have influenced and stimulated each other. Globalization, as well as the recent and planned enlargement of the European Union, has created a favourable climate for the intensive exchange of novel ideas, concepts and solutions. The Infosystem Forum plays an integrating role between computer science research, industry and consumers. The Poznań Linguistic Meetings have a long tradition as a linguistics exchange forum. This year we propose to add an explicitly technological dimension to this meeting and promote the Human Language Technologies to the industrial Infosystem audience, linking to the results of the very successful Language & Technology Awareness Days (Poznań, 1995), which served as a kick-off event for new HLT activities in Poland. We therefore invite colleagues from across the world to share with us their experience, recent results and new visions as well as to learn about our achievements. |
We invite the submission of original contributions.
The conference topics include but are not limited to:
|
|
Best papers authored by PhD students or regular students were awarded with the L&T Price. The Jury composed of the Programme Committee members present at the conference awarded the price to: Ronny Melz (University of Leipzig), Hartwig Holzapfel (University of Karlsruhe), Marcin Woliński (IPI PAN, Warsaw). |
| Zygmunt Vetulani (Adam Mickiewicz University, Poznań, Poland) - chair |
| Dafydd Gibbon (University of Bielefeld, Germany) - vice-chair |
| Leonard Bolc (IPI PAN, Poland) |
| Lynne Bowker (University Ottawa, Canada) |
| Nicoletta Calzolari (ILC/CNR, Italy) |
| Julie Carson-Berndsen (University College Dublin, Irland) |
| Khalid Choukri (ELRA, France) |
| Alain Colmerauer (Mediterranean University Aix-Marseille II, France) |
| Elżbieta Dura (University of Goeteborg/Lexware Labs, Sweden) |
| Katarzyna Dziubalska-Kołaczyk (Adam Mickiewicz University, Poznań, Poland) |
| Tomaz Erjavec (Josef Stefan Institute, Slovenia) |
| Charles Fillmore (Berkeley University, USA) |
| Maria Gavrilidou (ILSP, Greece) |
| Stefan Grocholewski (PTI/Poznań University of Technology, Poland) |
| Wacław Iszkowski (PIIT, Poland) |
| Zhou Jie (School of Computer Science and Engineering, South China University of Technology, China) |
| Orest Kossak (Technical University Lviv/Ericpol Telecom, Ukraine) |
| Eric Laporte (University Marne-la-Vallee, France) |
| Gerard Ligozat (LIMSI/CNRS, France) |
| Bente Maegaard (Centre for Language Technology, Denmark) |
| Jacek Martinek (Poznań University of Technology, Poland) |
| Toyoaki Nishida (University of Kyoto, Japan) |
| Antoni Ogonowski (Renault SAS, France) |
| Nicholas Ostler (Linguacubun Ltd., UK) |
| Karel Pala (Masaryk University, Czech Rep.) |
| Pavel S. Pankov (National Academy of Sciences, Kyrgyzstan) |
| Marcin Paprzycki (Oklahoma State University, USA) |
| Reinhard Rapp (University Mainz, Germany) |
| Justus Roux (University of Stellenbosch, South Africa) |
| Vasile Rus (University of Memphis, Fedex Inst. of Technology, USA) |
| Max Silberztein (University Franche-Comté, France) |
| Krzysztof Ślatała (MTP/Infosystem, Poland) |
| Marek Świdziński (University of Warsaw, Poland) |
| Dan Tufiş (RCAI, Romania) |
| Tom Wachtel (Independent Consultant, Italy) |
| Jan Węglarz (Poznań University of Technology, Poland) |
| Richard Zuber (CNRS, France) |
| Zygmunt Vetulani (Adam Mickiewicz University, Poznań, Poland) - Chair |
| Maciej Lison (Adam Mickiewicz University, Poznań, Poland) - Secretary |
| Jacek Marciniak (Adam Mickiewicz University, Poznań, Poland) |
| Tomasz Obrębski (Adam Mickiewicz University, Poznań, Poland) |
| Filip Graliński (Adam Mickiewicz University, Poznań, Poland) |
| Paweł Przybyłek (Adam Mickiewicz University, Poznań, Poland) |
| Contact: ltc@amu.edu.pl |
| Address: |
The 2-nd Language & Technology Conference (L&T'05) Adam Mickiewicz University Faculty of Mathematics and Computer Science Department of Computer Linguistics and Artificial Intelligence ul. Umultowska 87 PL 61-614 Poznań |
| E-mail: | ltc@amu.edu.pl |
| WWW: | www.ltc.amu.edu.pl |
|
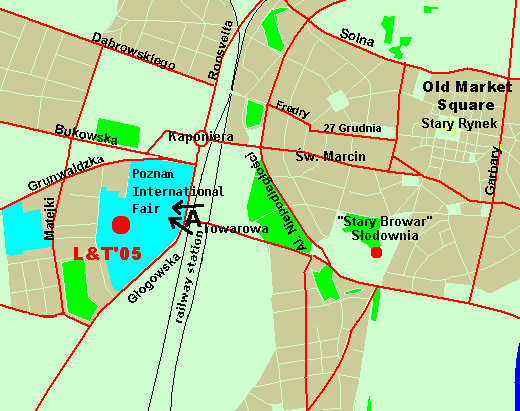 |
| A — Poznan Internation Fair, entrance A (the location of the L&TC'05 reception desk) |
| See also Poznan Internation Fair Grounds Map. |
The schedule of the Language and Technology ConferenceSee also the detailed programme of presentations Please note: the conference programme is final, no modifications will be accepted.
Program of technical sessions and invited talksThe programme can be downloaded as a DOC file. Each presentation should take 20 minutes (questions and discussion included). Day 1: 21.04.2005
9:45-10:30 Invited Talk I Recent Activities within the European Language Resources Association / Khalid Choukri and Victoria Arranz
11:00-13:00 Technical Sessions
Session 111: Speech Processing: Recognition
Efficient Phonetic Interpretation of Multilinear Feature Representations for Speech Recognition / Daniel Aioanei, Moritz Neugebauer and Julie Carson-Berndsen / Ireland This paper presents an approach to the phonetic interpretation of multilinear feature representations of speech utterances combining linguistic knowledge and efficient computational techniques. Multilinear feature representations are processed as intervals and the linguistic knowledge used by the system takes the form of feature implication rules (constraints) represented as subsumption hierarchies which are used to validate each interval. In the case of noisy or underspecified data, the linguistic constraints can be used to enrich the representations.
Accessing Language Specific Linguistic Information for Triphone Model Generation: Feature Tables in a Speech Recognition System / Supphanat Kanokphara, Anja Geumann and Julie Carson-Berndsen / Ireland This paper is concerned with a novel methodology for generating phonetic questions used in tree-based state tying for speech recognition. In order to implement a speech recognition system, language-dependent knowledge which goes beyond annotated material is usually required. The approach presented here generates phonetic questions for decision trees are based on a feature table that summarizes the articulatory characteristics of each sound. On the one hand, this method allows better language-specific triphone models to be defined given only a feature-table as linguistic input. On the other hand, the feature-table approach facilitates efficient definition of triphone models for other languages since again only a feature table for this language is required. The approach is exemplified with speech recognition systems for English and Thai.
Transcription-based automatic segmentation of speech / Marcin Szymański and Stefan Grocholewski / Poland The important element of today's speech systems is the set of recorded wavefiles annotated by a sequence of phonemes and boundary time-points. The manual segmentation of speech is a very laborous task, hence the need for automatic segmenation algorithms. However, the manual segmentation still outperforms the automatic one and at the same time the quality of resulting synthetic voice highly depends on the accuracy of the phonetic segmentation. This paper describes our metodology and implementation of automatic speech segmentation, emphasizing its new elements.
Accent Variation in South-African English: Challenges for Speech Recognition Systems / Edward de Villiers, Johan du Preez and Justus Roux / South Africa We present an experiment performed to determine whether it is better to model the various accent groups of South-African English separately or in one combined system. It is shown that combining the data achieves better results provided that equal quantities of training data are used from each accent group. We get the strange result that reducing the proportion of larger databases in the training set increases the score of those databases on the combined system.
A Multi-Layered Lexical-Tree Based Token Passing Architecture For Efficient Recognition Of Subword Speech Units / Andreas Hagen and Bryan L. Pellom / USA Pioneering research by MIT and CMU as well as more recent work by the IBM Watch-me-Read Project have demonstrated that speech recognition can play an effective role in systems designed to improve children's reading abilities (Mostow et al., 1994, Zue et al., 1996). In CMU's Project LISTEN, for example, the tutor operates by prompting children to read individual sentences out loud. The tutor listens to the child using speech recognition and extracts features that can be used to detect oral reading miscues (Mostow et al., 2002, Tam et al., 2003). Upon detecting reading miscues, the tutor provides appropriate feedback to the child. Recent results show that such automated reading tutors can improve student achievement (Mostow et al., 2003). In each of these previous works, and including our own earlier work in (Lee et al., 2004, Hagen et al., 2003, Hagen et al., 2004) the output words from the speech recognizer are used to provide key information needed to track the child's progress while reading. The confidence tagged word output is also used to provide information necessary to determine oral reading miscues (e.g., substitutions, deletions, and insertions of words). In (Lee et al., 2004), for example, we demonstrated that a speech recognition word error rate of 8% can be achieved during an oral reading task where children in grades 3 through 5 were asked to read a book out loud. We point out that while word-based speech recognition output provides a conceptually simple framework for reading tracking, such systems offer very limited capabilities to detect and model events such as the sounding out of words by children or miscues such as partial words, restarts, hesitations that can often occur during oral reading by early literate children. For example, consider the following sentence as read by a child, "It wa- was the first day of sum- ... -mer summer vacation". Current speech recognition systems based on word-length units inadequately model such events. In this paper we propose a new architecture for improved and efficient modeling of subword sequences
Session 112: Language Resources and Tools: Corpora
Digital Text Corpora at the AAC / Hanno Biber and Evelyn Breiteneder / Austria The AAC [Austrian Academy Corpus] is a corpus research institution based at the Austrian Academy of Sciences in Vienna. The AAC is a very large and complex electronic text collection. Its aims are to create an innovative text corpus and to conduct scholarly and scientific research in the field of electronic text corpora. In the first phase of the corpus build up the AAC is committed to have at least 100 million running words of carefully selected and scholarly annotated significant texts. The corpus approach of the AAC will allow a variety of investigations into the linguistic properties, the textual structures and the historical and literary significance of the selected texts. In the second phase of application development the size of the Austrian Academy Corpus will increase to around one billion running words. In this phase selected subcorpora will be annotated in greater detail following the AAC schemes for annotation and according to its editorial principles. The AAC working group is endeavouring to establish a corpus that meets the needs of textual studies and conveys essential information about the German language as well as about the history of the time in focus as a history of texts and of language.
The IPI PAN Corpus in Numbers / Adam Przepiórkowski / Poland The aim of this article is to present the IPI PAN Corpus (cf. http://korpus.pl/), a large morphosyntactically annotated XML encoded corpus of Polish developed at the Institute of Computer Science, Polish Academy of Sciences. Various quantitative information about the corpus and its publicly available subcorpora is given including: sizes in terms of orthographic words and interpretable segments, tagset size measured in types and tokens, etc., but also information reflecting interesting facts about Polish, i.e., frequencies of words of different lengths and frequencies of grammatical classes and some grammatical categories.
Massive multilingual corpus compilation: Acquis Communautaire and totale / Tomaž Erjavec, Camelia Ignat, Bruno Pouliquen and Ralf Steinberger / Italy, Slovenia The paper discusses the compilation of massively multilingual corpora, the EU ACQUIS corpus, and the corpus annotation tool "totale". The ACQUIS text collection has recently become available on the Web, and contains EU law texts (the Acquis Communautaire) in all the languages of the current EU, and more, i.e. parallel texts in over twenty different languages. Such document collections can serve as the basis for multilingual parallel corpora of unprecedented size and variety of language, useful as training and testing dataset for a host of different HLT applications. The paper describes the steps that were undertaken to turn the text collection into a linguistically annotated text corpus. In particular, we discuss the harvesting and wrapper induction of the corpus, and the usage of its annotation with EuroVoc descriptors. Next, the text annotation tool "totale" which does multilingual text tokenization, tagging and lemmatisation is presented. The tool implements a simple pipelined architecture which is, for the most part, fully trainable, requiring a word-level syntactically annotated text corpus and, optionally, a morphological lexicon. To train totale for seven different languages we have used the MULTEXT-East corpus and lexicons; we describe this resource and the training of totale, and its application to the ACQUIS corpus. Finally, we turn to the current experiments in aligning the corpus, and developments we plan to undertake in the future.
From regularities to constraints: Enriching annotation in discourse corpora / Claudia Sassen / Germany I will argue for an enriched annotation of corpora which is based on the tagging of moves and meant as addendum to existing annotations. I will propose some way of tagging the fulfilment and violation of constraints by an XML-based annotation which thereby allows to predict where rhetorical relations might occur: Only if all constraints are fulfilled between two discourse units a rhetorical relation can obtain between them. As a starting point, I will take two constraints which are pervasive in discourse, viz. Polanyi's Right Frontier Constraint and a constraint I will call Semantic Compatibility Constraint. This method acknowledges and supports Asher's and Lascarides' principle of Maximise Discourse Coherence (Asher and Lascarides, 2003).
Computational Tools for Elaboration and Functioning of a Multilingual Thematic Dictionary / Ilona Koutny / Poland The lexicographer's work has changed during the last years: his manual collecting of new words and expressions from written texts and spoken language over several years, and reliance on self-made examples have made way for the consultation of corpora. The standard language use can be represented by large-scale overall corpora of written and spoken language as found in the national corpora or similar ones (see §2). Online dictionaries and lexical databases also often constitute rich and more up-to-date resources. Series of thematic dictionaries manifesting semantic and pragmatic relations between the items are being worked out, where types, activities, attributes, and subordinated and associated notions are put under the headwords to offer a real context of usage (§3). Lexical and grammatical collocations are part of entries. Chapter 4 will illustrate how corpora can be applied to search for headwords and collocations, furthermore for determination of meaning and language variety. Some functions of the planned machine-readable multilingual dictionary will be outlined, considering its use in computer aided language learning (§5). from spoken language (interviews, speeches in parliament, informal conversations). The Collins Cobuild Corpus contains 450 million text words from modern British English (newspapers, technical literature, fiction, letters) where 4,4 % comes from spoken language (conversations, interviews and discussions on the BBC). The lexical database of WordNet provides synonyms, hyperonyms, hyponyms, troponyms, related notions, antonyms when available, sentence frames for verbs, and some other semantic relations in addition to the detailed meanings of a word. Longman Dictionary of Contemporary English on CD or WEB offers a treasury of collocations.
Session 113: Natural Language Understanding
NLP Story Maker / Takako Aikawa, Michel Pahud and Lee Schwartz / USA This paper explores a novel approach to linking Graphics and Natural Language Processing (NLP). Our tool, Story Maker, lets users illustrate their stories on the fly, as they enter them on the computer in natural language. Our goals in creating Story Maker are twofold: to explore the use of NLP in the dynamic generation of animated scenes, and to explore ways to exploit users' input in order to obviate the necessity of having a large database of graphics. With our NLP technology, users can input unrestricted natural language. Story Maker provides users with direct visual output in response to their natural language input. The tool can potentially impact both the way we interact with computers and the way we compose text.
Analysis of the natural language means used for the representation and understanding of formal knowledge / Elena Gennadievna Ivanova / Russia The goal of this article is to define the basic set of requirements for a language (natural as well as artificial) used in the communication process between intelligent agents. These requirements represent: 1) the minimal and sufficient set of means, having which a language will be able to represent any type of formal knowledge; 2) the minimal and sufficient set of rules , following which the information expressed by natural language will be correctly understood by all agents.
Grounding Linguistic Quantifiers in Perception: Experiments on Numerosity Judgments / R.K. Rajapakse, A. Cangelosi, K. Coventry, S. Newstead and A. Bacon / UK The paper presents a new computational model for the grounding of numerosity judgments and of the use of linguistic quantifiers. The model consists of a hybrid, artificial vision-connectionist architecture. Preliminary simulation experiments show that the part of the model trained to judge "psychological number" uses some of the same factors known to play a major role in the production of quantification judgments in human subjects. This supports the ongoing development of a psychologically-plausible model of linguistic quantifiers which uses the contextual factors such as object properties and their functionality.
(V)ISA: A Model for Transforming Genitive Phrases Into SQL Statements / Zsolt T. Kardkovács, Domonkos Tikk, Gábor Magyar / Hungary In our ongoing project called "Web of Words" (WoW) we aimed to create a Hungarian question processor specially designed for querying the deep web. One of the most crucial parts of the system was the transformation of genitive relations into both XPath and SQL, since common questions (e.g. those begin with "Who" and "What") usually contain such an expression. Transformation of genitives by algorithms is a hard task since wide range of different relations can be expressed by genitive phrases. In this paper, we focus on the transformation of syntactically analyzed genitives into SQL statements and we propose theoretical foundations and general considerations. Our results can be easily adopted for some closely related fields of study.
Crossing the Cognitive Barrier - Mapping Speech Streams to Conceptual Structures / Ronny Melz / Germany A very old question of language technologies is how to approach the meaning of language, i.e. the automatic association of meaning to words. The software presented in this contribution actually simulates conceptual awareness. A naturally spoken speech stream is converted into a word stream (speech-to-text), the most significant concepts are extracted and associated to further related concepts, which have not been mentioned yet by the speaker(s). The result is output on the screen and shows associations as conceptual graphs.
14:15-15:00 Invited Talk II In memoriam Maurice Gross / Eric Laporte
15:05-16:30 Technical Sessions
Session 121: Language Resources and Tools: Text Processing Techniques I
Compressing Annotated Natural Language Text / Jakub Swacha / Poland The paper is devoted to description and evaluation of a new method of linguistically annotated text compression. A semantically motivated transcoding scheme is proposed in which text is split into three distinct streams of data. By applying the scheme it is possible to reduce compressed text length by as high as 67%, compared to the initial compression algorithm. An important advantage of the method is the feasibility of processing text in its compressed form.
Analyzing the Effect of Dimensionality Reduction in Document Categorization for Basque / Ana Zelaia, I. Inaki Alegria, Olatz Arregi and Basilio Sierra / Spain This paper analyzes the incidence that dimensionality reduction techniques have in the process of text categorization of documents written in Basque. Classification techniques such as Na¨ve Bayes, Winnow, SVMs and k-NN have been selected. The Singular Value i Decomposition (SVD) dimensionality reduction technique together with lemmatization and noun selection have been used in our experiments. The results obtained show that the approach which combines SVD and k-NN for a lemmatized corpus gives the best accuracy rates of all with a remarkable difference.
Automatic Phonetization and Syllabification of Italian Texts / Mario Refice and Michelina Savino / Italy This paper presents the results of a work carried out in collaboration with CERIL/LADL, Paris, under the supervision of Maurice Gross at the very beginning of the Nineties, and represents a small contribution to his memory and a a sign of our gratitude to him for his help in pursuing the aim of integrating technological background with a more linguistically oriented approach in dealing with research issues on natural language processing. The work refers to the automatic production of pronunciation dictionaries of Italian inflected forms, and the main tasks performed by the implemented algorithm are the syllable division on the orthographic string, the grapheme-to-phoneme conversion of the syllabified string and the syllabification of the phonemic string.
Exploring deployment of linguistic features in Classification of Polish Texts / Jakub Piskorski and Marcin Sydow /Poland This paper reports on some preliminary experiments of deploying linguistic features for classification of Polish texts. In particular, we explore the impact of lemmatization and various term-selection strategies relying on inclusion and exclusion of certain named-entity classes. A slight improvement against the bag-of-words approach can be observed, but there is still a lot of place for improvement.
Session 122: Language Resources and Tools: Morphology Processing
Making the Good Taggers Even Better: Application of Artificial Neural Networks in Morphological Tagging of Czech / Petr Nemec and Kiril Ribarov / Czech Republic Morphological tagging is an important problem in the area of computational linguistics as it underlies other crucial tasks such as syntactic parsing and machine translation. Nowadays, the problem is being most commonly solved by a statistical approach. Artificial neural networks (ANN) represent another promising approach to this kind of problems for which the exact algorithmic solution is unknown or not efficient enough. In this paper we present the results obtained by application of the well-known backpropagation (BP) neural network in several types of experiments. We have focused on the Czech morphology, because its morphological system is very rich and no experiments concerning application of artificial neural networks have been carried out for this language. First, we have verified on a set of preliminary experiments that the neural network is capable of capturing the Czech morphology, which, secondly, served also for determination of appropriate network and context parameters. Thirdly, we have used neural networks for a voting experiment. The aim of the voting experiment was to select the correct tag (if present) from the outputs of two statistical taggers, the Markov model tagger and the Feature-based tagger. In this experiment, BP showed higher tagging precision (93.56%) than any of the input statistical methods (92.74%, 92.58%) and exceeded even the currently best available statistical result (93.47%). BP has proved to be a worthy post-processing tool that is able to perform implicit evaluation on complementary aspects of different statistical approaches.
MAF: a Morphosyntactic Annotation Framework / Lionel Clément and Éric Villemonte de la Clergerie / France In the context of ISO Sub-Committee TC37 SC4 for the normalization of linguistic resources, we are promoting a framework for handling morpho-syntactic annotations. This paper sketches the main ideas of this proposal based on a two level structuring for tokens and word forms, ambiguity handling through lattices, use of feature structures for morpho-syntactic content, and mechanisms to define comparable tagsets.
Morphological Analyser Based on Finite State Transducer: A case study for Oriya Language / Chinmaya Kumar Swain, Prabhat Kumar Santi and Sanghamitra Mohanty / India This paper deals with the effective design and implementation of the morphological analyser of Oriya, which is a morphologically rich language derived from Sanskrit. The most of the morphemes in Oriya coordinate with the root words in the form of suffixes. Information such as Part of Speech (PoS), Case-relation, number, person, tense, aspect and mood are all conveyed through morphological attachments to the root of nominal or verbal words. This makes morphological analyser and generator of Oriya words a challenging task which is very essential tool in the area of Machine Translation, Parser, Spell Checker, OriNet (WordNet for Oriya), PoS tagging etc. This paper elucidates the simple and efficient computational model for Oriya morphology based on finite state transducers.
Morphology-based Spellchecking for Marathi, an Indian Language / Veena Dixit, Satish Dethe and Rushikesh K. Joshi / India Morphological analysis is a core component of Technology for Indian languages. This paper outlines issues related to spellchecking of documents in Marathi, an Indian language. Issues for both orthography and morphology are discussed. Morphological analysis has been applied to a large number of words of different parts of speech. Architecture for spellchecker and a spell-checking algorithm based on morphological rules is outlined.
Session 123: Ontologies I
Use of subject domain ontology for problem-oriented speech processing / Izolda Lee / Russia As is well known, the construction of understanding model is based on the purpose of a system and, in many respects, is defined by a subject domain (SD), which can be characterized by concepts (terms) hierarchy. The system of automatic speech understanding should generalize concepts (terms) correctly. For this purpose, it is necessary to use the knowledge of concept relations within the framework of a certain SD. In this paper, the solution of the problem of accounting concepts hierarchy is proposed by a domain ontology. The ontology is presented as a tree of concepts of a SD in a xml-format, which simplifies the expansion of both an ontology and the vocabulary of a SD. The developed verification method of an ontological subset of a hypothesis of the input utterance insures flexibility of automatic understanding system toward natural language phrases containing concepts of a various levels of generalization within a certain SD, without loss of speed and quality of speech processing.
Semantic annotation of hierarchical taxonomies / Agnieszka Ławrynowicz / Poland Most of the document repositories is organized with the use of hierarchical taxonomies (HTs). To examples of HTs belong file systems, marketplace catalogs, Web directories. Underlying content is associated with the nodes in the hierarchical structure where each node represents certain concept described by the node label and its position in the hierarchy. By default, users browse hierarchy of concepts to access documents associated with them. While accessing documents users have the implicit meaning of the particular node in mind. Meaning of the node depends not only on the label of the node, but also on the position of the node in the hierarchy. The goal of this work is to develop a method for making implicit node meanings explicit - that is given a concept hierarchy, return an interpretation of each node of a hierarchy in terms of a logical formula. This explicit, semantic node annotation can be an important step in many of existing and emerging applications like automatic mapping between catalogs, schema matching, ontology mapping in the Semantic Web or services discovery and composition. For example, the problem of HTs interoperability may occur when two companies (possibly participating in electronic marketplace) want to exchange their products without a common product catalog. In this case mappings between their catalogs are needed. Another example is an automatic annotation of the Web site content to extract the domain ontology useful for the semantic description of content and services of the Web site that can be further used by software agent searching for a particular service on the Web. There have been approaches related to semantic annotation of taxonomies like the work presented in (Woods, 1997) on conceptual indexing that automatically organizes all of the words and phrases from documents to build a conceptual taxonomy that explicitly links each concept to its most specific generalizations. In (Missikoff et al, 2002) terms automatically extracted from documents are semantically interpreted with WORDNET lexical database (Fellbaum, 1998) and relations between synsets are used to organize concepts into trees. In (Kavalec & Svatek, 2002) the structure of Web Directories headings is interpreted in order to obtain labeled training data for Information Extraction from Web documents. In our work we draw from the approach
Design and Implementation of Nouns in OriNet: Based on the Semantic Word Concept / Prabhat Kumar Santi, Sanghamitra Mohanty and K.P. Das Adhikary / India OriNet (WordNet for Oriya language) is an on-line lexical database in which Oriya nouns, verbs, adjectives, adverbs and indeclinable have been organized through semantic relations such as synonym, antonym, hypernym, hyponymy, meronym, holonym and entailment. The semantic relations of noun concept in OriNet have been organized as per the explanation of WordNet and Indian logic. Besides, some other relative information such as "English meaning", "definition", "examples", "syntactic category", "morphology" etc., have been provided in each noun concept. The organization is informative and relational, which involves the above semantic relations that any information regarding a noun concept can be obtained. The system is designed on the basis of file management system having user-friendly browser. Keywords: WordNet, OriNet, NNP, Synset, Unique Beginners, Hypernym & Hyponym.
Multilingual Ontology of Proper Names / Cvetana Krstev, Duško Vitas, Denis Maurel and Mickaël Tran / France This paper deals with a multilingual four-layered ontology of proper names. This ontology is organized around a conceptual proper name that represents the same concepts in different languages.
17:00-19:10 Technical Sessions
Session 131: Language Resources and Tools: Dictionaries
Maurice Gross' grammar lexicon and Natural Language Processing / Claire Gardent, Bruno Guillaume, Guy Perrier and Ingrid Falk / France Maurice Gross' grammar lexicon contains an extremly rich and exhaustive information about the morphosyntactic and semantic properties of French syntactic functors (verbs, adjectives, nouns). Yet its use within natural language processing systems is still restricted. In this paper, we first argue that the information contained in the grammar lexicon is potentially useful for Natural Language Processing (NLP). We then sketch a way to translate this information into a format which is arguably more amenable for use by NLP systems.
A Dictionary of French Verbal Complementation / Morris Salkoff and André Valli / France We are constructing a complete dictionary of French verbal complementation using available dictionaries, the tables of verbal constructions at LADL, and in a large measure, the data base available at Google.fr. The latter turns out to be a more fruitful source of verbal arguments than even the largest French dictionaries (e.g. the TLF), and reflects contemporary French usage correctly, after illiterate productions are ignored. The results are striking: a large percentage of French verbal arguments are not to be found in the standard dictionary sources, nor in sources available on the Internet. The large amount of data on arguments containing prepositional phrases that will be compiled during this study should prove useful to researchers in NLP working on the French language.
Building Multilingual Terminological Lexicons for Less Widely Available Languages / Monica Monachini and Claudia Soria / Italy Language Resources are central components for the development of Human Language Technology applications. The availability of adequate Linguistic Resources for as many languages as possible plays a critical role in view of the development of a truly multilingual information society. It is no mystery that the task of producing language resources is an extremely long and expensive process. For most western languages, and English in particular, however, this is partly mitigated by large and often free data availability, good representativeness, and significant size, together with availability of language processing tools. There is plenty of languages, however, for which this picture is far from being adequate. Many languages actually suffer from poor representation and scarcity of raw material, not to mention the availability of robust processing tools. It is imperative to try to reach a balance of language coverage in order to avoid a two-speed Europe (Maegaard et al. 2003). This awareness gave rise to coordinated efforts, both at national and European level, in the direction of reducing this gap (Calzolari et al. 2004) and enabling less-favoured languages with respect to language technology. The concepts of BLARK, i.e. the definition and adoption of a standard Basic Language Resource Kit for all languages, a minimal set of language resources necessary to the development of language and speech technology (Krauwer 1998), goes exactly in this direction. In INTERA, the expression "less widely available languages" has to be interpreted in the sense of (Gavrilidou et al. 2003, Gavrilidou et al. 2004), that is, of "less widely available in the digital world". This concept has been developed in response to a survey, also conducted in the framework of the INTERA Project, aimed at the identification of users' needs and expectations concerning language resources. Although western European languages have been confirmed as having the highest amount of request, the survey clearly demonstrates that there is an increase in demand for Balkan and eastern European languages. Under this respect, it has to be noted that the notion of "less widely
Lexicons Divided According to the Division of Labor / Yukiko Sasaki Alam / Japan Focus of the current research is on the lexicon in natural language processing. The structure and contents of the lexicon are a vital issue to be addressed, yet much explicit discussion on them as a whole is not out. This paper proposes a model that performs morphological, syntactic and semantic analyses by using three levels of lexicons. The first level of lexicon is for morphological analysis, and lists the strings of the morphemes of a language, the morphological properties and the syntactic categories, whereas the second level is for syntactic analysis, and consists of several dictionaries divided according to the syntactic categories and subcategories. Each of the second level of dictionaries provides information on the meanings of words. Verbs are listed in syntactically subcategorized dictionaries such as a dictionary for NP/V/VCOMPP or NP/V/SCOMPP and a dictionary for NP/V/NP. The third level of lexicon is a semantic lexicon, indexed with unique meanings, and furnished with information on the semantic classes of the meanings, so that each meaning could attain more information relating to the class from the table of semantic classes. The third level of semantic lexicon is intended for all languages. For a comprehensive view of the model, the present paper elaborates a step-by-step process of parsing an English sentence in interaction with the relevant dictionaries.
Derivational Morphology in an E-Dictionary of Serbian / Duško Vitas and Cvetana Krstev / Serbia & Montenegro In this paper we explore the relation between derivational morphology and synonymy in connection with an electronic dictionary, inspired by the work of Maurice Gross. The characteristics of this relation are illustrated by derivation in Serbian, which produces new lemmas with predictable meaning. We call this regular derivation. We then demonstrate how this kind of derivation is handled in text processing using a morphological e-dictionary of Serbian and a collection of transducers with lexical constraints. Finally, we analyze the cases of synonymy that include regular derivation in one aligned text.
Session 132: Information Retrival / Information Extraction I
Generation of Reference Summaries / Martin Hassel and Hercules Dalianis / Sweeden We have constructed an integrated web-based system for collection of extract-based corpora and for evaluation of summaries and summarization systems. During evaluation and examination of the collected and generated data we found that in a situation of low agreement among the informants the corpus gives unduly favors to summarization systems that use sentence position as a central weighting feature. The problem is discussed and a possible solution is outlined.
Keyword-based Coreference Resolution for Enzyme Name Recognition / Chun Xiao and Dietmar Rösner / Germany We aim at recognizing enzyme names in biomedical abstracts. Starting with a substring-based process for enzyme name recognition, we propose and test a keyword-based model for coreference resolution in order to improve the recognition performance.
Pseudo-Relevance Feedback with Weighted Logistic Regression / Zhaohui Zheng, Wei Dai and Rohini Srihari / USA Pseudo-relevance feedback (PRF) is an effective technique commonly used to improve retrieval effectiveness. We propose a novel method for applying logistic regression to PRF. In this technique, each query itself and the top-ranked documents are considered as positive training examples, but weighted differently according to their relevance to the query. Experiments are conducted on standard TREC collections in two retrieval tasks: document retrieval and sentence retrieval. The results demonstrate its effectiveness over the Rocchio algorithm.
Exploration of Subtopic Retrieval with Document Set Ranking / Wei Dai and Rohini Srihari / USA This paper presents a novel formulation and approach to the minimal document set retrieval problem. Minimal Document Set Retrieval (MDSR) is a novel information retrieval task in which each query topic is assumed to have different subtopics; the task is to retrieve and rank relevant document sets with maximum coverage but minimum redundancy of subtopics in each set. For this task, we propose three document set retrieval and ranking algorithms: Novelty Based method, Cluster Based method and Subtopic Extraction Based method. In order to evaluate the system performance, we design a new evaluation framework for document set ranking which evaluates both relevance between set and query topic, and redundancy within each set. Finally, we compare the performance of the three algorithms using the TREC interactive track dataset. Experimental results show the effectiveness of our algorithms.
Structural Ambiguity In Context / Jean-Baptiste Berthelin / France We designed a tool for exploring the Web and looking for a special kind of structural ambiguity, namely, French sentences where the central component can be either an adjective or a verb. Using this tool, we can actually count how many cases of such sentences are produced by Web users, and which reading for them is generally preferred.
Information Retrieval Based on Semantic Structures / Takashi Miyata and Koiti Hasida / Japan An interactive information retrieval system is described herein. It is based on graph matching between semantic structures obtained from syntactic dependencies. The system proposes query revisions to a user depending on both the structure of the query and the structures of sentences in a database. A preliminary experiment suggests that semantic structures can contribute to the efficiency of interactive information retrieval to some extent. Structure-sensitive word similarity does not work as well as expected because some subjects input `inappropriate' structures.
Session 133: Rigorous Descriptions of Languages
A Simple CF Formalism and Free Word Order / Filip Graliński / Poland The first objective of this paper is to present a simple grammatical formalism named Tree-generating Binary Grammars. The formalism is weakly equivalent to CFGs, yet it is capable of generating various kinds of syntactic trees, including dependency trees. Its strong equivalence to some other grammatical formalisms is discussed. The second objective is to show how some free word order phenomena in Polish can be captured within the proposed formalism.
Restructuring Świdziński's grammar of Polish / Maciej Ogrodniczuk / Poland The article presents initial results of two changes applied to Swidziński's formal grammar of Polish: restructurization of the grammar to eliminate redundant cycles and its extension with nominal group definition (as defined by Szpakowicz and Swidzi´ ski). A short n summary on the results of parsing the suite of test sentences with the original and modified variants of the grammar is also included.
Proper treatment of some peculiarities of Polish numerals: metamorphosis approach / Marek Świdziński / Poland The aim of the paper is to show how some idiosyncratic features of Polish constructions with numerals can be formally accounted for in the framework of a certain metamorphosis grammar (Colmerauer, 1978, Abramson & Dahl, 1989, FGP). Such constructions have a reputation of most troublesome structures of Polish syntax. It will be shown below that what is system-singular phenomena need not require sophisticated formal means to have them properly defined. The formal definition of Polish referred to below is given in Gramatyka formalna jzyka polskiego [Formal grammar of Polish] by M. widziski (FGP). FGP happens to lack rules accounting for numeral structures. The high frequency of such structures is a good reason to add a set of rules to FGP. In what follows we develop and push forward some ideas taken from widziski, Derwojedowa & Rudolf, 2003. We will not discuss recent publications on Polish numerals here as we would like to present our technical approach in detail, rather than compare ours with other. Let us mention three papers we have, to some extent, been inspired by: Rutkowski, 2002a, 2002b (generative account), and Przepiórkowski, 2004 (HPSG account). With all this, it should be emphasized that our approach, though "generative" in the broad sense, does by no means locate within the Chomskyan paradigm. By a numeral we understand here a syntactic unit distributionally equivalent to a word form of a lexical unit belonging to the part of speech called numerals. Similarly, a verb is a word form of a verbal unit. Of more than 10 morphological and syntactic peculiarities of Polish numerals, three will be considered below: ˇ distributional nonequivalence of "nominal proper" and numeral-nominal NP's, ˇ incompatibility of internal and external gendernumber characteristics of some numerals, and ˇ some strange long-distance agreements.
Constraint Weighting by Evolution / Henk Zeevat / Netherlands Constraints in optimality theory are normally ranked as a function of their actual occurrence in a corpus of learning data. The paper makes the case that for expressive constraints in particular those that force the marking of theta-roles and topic- it is possible to derive their ranking directly from the evolutionary pressure to mark the feature in question and explains the connection between this ranking and a concept of linguistic evolution. A second claim is that expressive constraints are (or can be seen as) locally bidirectional and can freely rank with other constraints. This appears to be the only way to obtain the effect of word order freezing in optimality theory, all other theories run into problems with at least one of the data to be explained.
Automatic Extraction of Polish Verb Subcategorization: An Evaluation of Common Statistics / Jakub Fast, Adam Przepiórkowski / Poland This article compares and evaluates common statistics used in the process of filtering the hypotheses within the task of automatic valence extraction. A broader range of statistics is compared than the ones usually found in the literature, including Binomial Miscue Probability, Likelihood Ratio, t Test, and various simpler statistics. All experiments are performed on the basis of morphosyntactically annotated but very noisy Polish data. Despite a different experimental methodology, the results confirm Korhonen's findings that statistics based solely on the number of occurrences of a given verb and the number of cooccurrences of the verb and a given frame in general fare much better than statistics comparing such conditional frame frequency with the unconditional frame frequency.
Lexicon Grammar within the Defining Matrix Analysis Model / Amr Helmy Ibrahim / France This paper argues why the natural development of Maurice Gross's lexicon-grammar framework that has it's roots in Zellig Harris's applicative grammar based on a clear cut distinction between report and paraphrase is Amr Ibrahim's Defining Matrix Analysis Model based on different grammatically driven reductions of the redundancies of the largest defining matrix of an utterance built through a series of controlled paraphrases.
Day 2: 22.04.2005
9:00-9:45 Invited Talk III Logical Types in Grammar. The heritage of Kazimierz Ajdukiewicz / Wojciech Buszkowski
9:50-11:00 Technical Sessions
Session 211: Language Resources and Tools: Text Processing Techniques II
Automatic analysis of French newspaper headlines / Harald Ulland / Norway In this paper we will discuss different methods of automating the syntactic and semantic analysis of French newspaper headlines. In order to achieve such an analysis, a division of each headline into fields is necessary. A thematic field as well as a scenic field may occupy the position in front of the predicate/argument fields. Some linguistic issues involved are clitics, auxiliaries and predicative nouns. The automatic analysis is performed by means of the Unitex analyzer. 1. Introduction Very often, newspaper headlines have the semantic structure of a predicate with argument(s). We will have a look into various ways of performing an automatic recognition of the predicate and, subsequently, its arguments in each headline. 2. Predicate/argument structure in headlines The first distinction to be made is the one between headlines with and headlines without a predicate/argument structure. We will assume that whenever a headline has the form of a sentence, there is such a structure. The problem is to make clear what type (s) of non-sentential headlines are predicative. One example would be the case of ellipses , where the verb (or its auxiliary) has been omitted, like the following example:L'oligarque Roman Abramovitch rattrapé par la BERD
Accessing Heterogeneous Linguistic Data - Generic XML-based Representation and Flexible Visualization / Stefanie Dipper and Michael Götze / Germany Annotation of linguistic data increasingly focuses on information beyond the (morpho-)syntactic level. Moreover, annotated data of less-studied languages is growing in importance. To maximally profit from this data, straightforward and user-friendly access has to be provided. In this paper, we describe a linguistic database that is accessed via a web browser and offers flexible visualization of multiply annotated data. Data is internally represented by a generic XML-based format.
Using Category Hierarchies for Correcting Category Errors in Multi-labeled Data / Fumiyo Fukumoto and Yoshimi Suzuki / Japan This paper presents a method for correcting category annotation errors in multi-labeled data which deteriorate the overall performance of text classification. We use the hierarchical structure for this purpose: we use it as a simple heuristics, i.e. the resulting category should be the same level, parent or child of the original category assigned to a document. Experimental results with the Reuters 1996 corpora show that our method achieves high precision in detecting and correcting annotation errors. Further, results on text classification improves accuracy.
Session 212: Information Retrival / Information Extraction II
A Survey of Freely Available Polish Stemmers and Evaluation of Their Applicability in Information Retrieval / Dawid Weiss / Poland Stemmers are computer programs for transforming all inflected forms of a word into a token representing its broader meaning. There are many openly available stemmers for English and other Indo-European languages, but until very recently stemmers for Polish were mostly commercial. In this paper we provide a survey of free and open source stemmers for Polish that came into view in the period of the last two years. We additionally present results from an experiment comparing these stemmers with two fully-fledged morphological analyzers.
Sentence Extraction using Similar Words / Yoshimi Suzuki and Fumiyo Fukumoto / Japan In both written and spoken languages, we sometimes use different words in order to express the same thing. For instance, we use "candidacy" (rikkouho) and "running in an election" (shutsuba) as the same meaning. This makes text classification, event tracking and text summarization difficult. In this paper, we propose a method to extract words which are semantically similar to each other accurately. Using the method, we extracted similar word pairs on newspaper articles. Further, we performed sentence extraction of news articles. We hypothesize that the headline is salient information of the news and presence of headline terms in the article can be used to detect salient sentences of news text. By using similar words in the headline, we obtained better results than that without using it. The results suggest that the method is useful for text summarization.
Making Shallow Look Deeper: Anaphora and Comparisons in Medical Information Extraction / A. Mykowiecka, M. Marciniak and A. Kupść / Poland The paper focuses on resolving natural language issues which have been affecting performance of our system processing Polish medical data. In particular, we address phenomena such as ellipsis, anaphora, comparisons, coordination and negation occurring in mammogram reports. We propose practical data-driven solutions which allow us to improve the system's performance.
Session 213: Ontologies II
Towards the Linking of two Electronic Lexical Databases of Italian / Nilda Ruimy and Adriana Roventini / Italy In this paper we address the issue of the semiautomatic link of ItalWordNet and PAROLE/SIMPLE/CLIPS, two electronic lexical databases of Italian language, based on different lexical semantic models with their own underlying principles and peculiarities. Nevertheless, the two resources present many compatible aspects that led us to take their analysis further, convinced that a considerable gain could be achieved by their link. In this paper, an outline of the mapping of both their ontological frameworks and semantic relations is provided, the linking methodology and related problems are then described, finally the reciprocal benefits and enhancements the two lexicons would gain from their linking are illustrated.
Ontological Approach to Meaning / Marek Łabuzek / Poland In the paper, an approach to the definition of meaning of natural language is presented, which utilises a concept of ontology to formalise the structures representing the meaning. It is claimed to be a good base for not only implementation of a software system analysing the meaning of texts but also for a rightful theory of truth. Some interesting observation concerned with meaning of plurals are described together with application of the framework in the field of requirement engineering.
Application Ontology Development - a Case Study / Jolanta Cybulka and Jacek Martinek / Poland The paper reports on a research concerning the creation of the application ontology for the area of life regulated by the statute on social security. Ontology is a specialization of Core Legal Ontology, which is in turn anchored in DOLCE foundational ontology. The created ontology should serve the conceptualization of some aspects of the world knowledge as well as the representation of the taskoriented knowledge.
14:15-15:00 Invited Talk IV Antonio Zampolli. A life for Computational Linguistics / Nicoletta Calzolari
Day 3: 23.04.2005
8:45-9:15 Invited Talk V Challenges of Applied Linguistics in Modern Ukraine / Nadija Andrejchuk and Orest Kossak
9:20-10:25 Technical Sessions
Session 311: Speech Processing: Synthesis
The long vowels in Standard Arabic. Application for speech synthesis with Mbrola / Kamel Ferrat / Algeria In Standard Arabic language, the long vowels called "huruf al-madd" represents a very important phenomenon. Our present work will contribute to modeling long vowels in order to synthesize speech using Mbrola method. Indeed, we are going to study vowels temporal durations and formants' values, as wel as the modifications undergone by long vowels energy graphs in relation to short vowels' ones. For it, we are going to use the Computering Speech Laboratory CSL of Kay Elemetrics together with the Praat and Matlab Windows Programs. Concerning the application on speech synthesis in Standard Arabic, we will use the Mbrola method (Multi Band Re-synthesis Overlap Add) witch is considered as one of the most efficient methods in terms of natural speech. Keywords: arabic speech synthesis, Mbrola, vowels, huruf al-madd, formants, energy. durations and the formantics values of the vowels and the modifications undergone by the graphs of the energy. We applied the found models to synthesize the Standard Arabic speech using the Mbrola method. Many researchers showed interest in developing systems synthesis capable to produce multilingual speech. The integration of the lingual variations within the same synthesiser appears to us essential, so that the systems of synthesis would be of an universal range. The MBROLA project, initiated in 1992 by the Polytechnic Faculty of Mons (Belgium) answers this preoccupation. It proposes an algorithm of synthesis using the concatenation of diphones.
The Etalone Method in Phonetic Research in Slavonic and Germanic Languages / Natalia Nikulina and Usewalad Nikulin / Poland The article presents a new quantitative method of phonetic research, the etalone method. In particular, the article addresses its structure, use and results obtained so far in the study of phonetic interference in Slavonic and Germanic languages: quantification of characteristics of phonetic interference in the Belorussian and English languages. The etalone method is a specific phonetic method of creating a structured model of an object or a phenomenon aimed at its comprehensive description. It can be used in different fields of linguistics, however, is characteristic of phonetic interference The method is based on the presumption that a person perceives language on three separate phonetic levels: the level of meaning, or the sense level, the acoustic level and the perception level It is primarily used for: 1) objective verification of scientific hypotheses of linguists and phoneticians; 2) comprehensive formalized description of languages, that allows for simple, easy-to-use and inexpensive language corpora; 3) discerning and separating correctly the intermixing characteristics of individual languages. The etalone method includes: 1) on the level of perception: the description of basic prosodic structures based on auditory and computer based analysis of approximately 100 texts of a given language, pronounced by the speakers, specially selected to eliminate the gender, age and other demographic factors; 2) on the acoustic level: the analysis of the recorded material on the basis of four basic and two additional acoustic parameters with the help of three-part mathematical and statistical analysis, covering at least 95% of interrelationships within the text; 3) on the level of meaning: the description of the rules governing the distribution of sense within the texts, specific sense characteristics of individual languages and models of their distribution in the text. To use this method for verification of a scientific hypothesis the researcher should: 1) formulate a hypothesis; 2) collect relevant material; 3) analyze it with the help of traditional methods and then preliminarily accept or reject the hypothesis; 4) either select or create the etalone relevant to research; 5) identify part of the etalone relevant to research; 6) compare research material to the relevant part of the etalone and make conclusions and resolve the task; 7) compare the results achieved by traditional methods and the etalone method correcting the traditional methods wherever possible. The procedure of the use of the etalone method for discerning and separation of intermixing structures of different languages implies: 1) selection or creation of the etalones of intermixed languages; 2) comparing the material in question with the etalones of intermixed languages; 3) identifying the structures belonging to each language. In our research we used both traditional methods of experimental phonetic study such as auditory and acoustic analyses as well as modern mathematical and statistical analyses. In accordance with the goals and objectives of the research we have chosen two types of monological speech for analysis of BelorussianEnglish prosodic interference: the lecture on linguistics based on the written text and the talk about a visit to a foreign country. Texts were selected on the basis of the following criteria: 1) compositional consistency; 2) sufficient length (20-25 utterances); 3) monological speech; 4) scientific and official styles; 5) similar themes in compared languages. The speakers were selected on the basis of the following criteria:
Speech synthesis of Polish based on the concatenation phonetic-acoustic segments / Grażyna Demenko / Poland The paper concerns speech synthesis based on the concatenation of phonetic-acoustic units for the Polish language in a module of a concatenative TTS system. For test synthesis purposes, all Polish diphones in various phonetic-acoustic contexts (8000 units) as well as a small corpus of continuous speech (a few hundred sentences) were selected from a Polish database including various speech units (diphones in logatoms and real words, CVC triphones in logatoms, consonant clusters in real words, the phrases with most common segmental and suprasegmental structures, read dialogues and monologues). The flexible choice of segmented units (words, syllables, phones) allowed optimized concatenation. For prosody modeling, only fundamental types of structures were distinguished, such as word and phrase accent placement or phrase boundary type. For phoneme duration modeling we used the CART alghorithm based on the language specific rhythm structure, e.g. for Polish we used the phone type, the context of adjoining phonemes, and the number of syllables in the foot. A number of speech synthesis techniques were taken into account and tested in the project. MBROLA and PROFIVOX used diphones extracted from isolated phrases. ORATOR (own program) used the technique of triphone signals' connection and modification. A pilot version of speech synthesis based on a corpus of continuous speech was implemented in BOSS (Multilingual Bonn Open Synthesis System), which is a new open architecture system for unit-selection-based speech synthesis allowing flexible use of its components and corpora. All the above mentioned systems produced fully comprehensible speech. The quality of the triphone-based synthesis substantially surpassed the quality of the diphone-based one. The most naturally-sounding speech was produced by the corpus-based speech synthesis system, BOSS. 1. Introduction The realization of a text-to-speech system, which performs the automatic conversion of a written text (for instance, typed on a keyboard or scanned) into not only comprehensible but also natural speech is one of the most ambitious goals of speech synthesis. Such systems are nowadays intensively developed for both theoretical and practical purposes (Gardner-Bonneau D. 2003, Narayanan S. & Alwan A. 2004). There are two main approaches towards segmental speech synthesis. The first of the two is synthesis based on rules which uses phonetic-acoustic knowledge (Baily et al, 2003). The second approach, dictionary synthesis, uses extensive databases and consists of linking longer or shorter phonetic-acoustic segments, such as (most frequently) diphones defined as parts of the speech signal starting from a steady state of the preceding phoneme (usually the middle of the phoneme) to a steady state of the following phoneme. Both above mentioned approaches have specific drawbacks. In the synthesis based on rules there are problems with co-articulation modeling, whereas the concatenative corpus-synthesis is insufficiently flexible (the material for synthesis has to be defined in the database). Furthermore, the choice of diphones or triphones as units for concatenation is controversial. It ensures a relatively economic language representation but with the false assumption (regardless of a language) that co-articulation pertains to adjacent segments only. 2. Speech corpus construction The problem of constructing an effective linguistic structure database for a flexible concatenative synthesis has been not solved for Polish or any other language (Hess W., 2004; Hoffmann R.,1999). The results of the phonetic-acoustical analysis of Polish speech units (consonant clusters, triphones) showed quite clearly the importance of the coarticulatory effects that depend on phonetic features, style and speech tempo. For this reason we have decided to use various speech units from different databases for the concatenative speech synthesis. The speech corpus used in our research consists of : ˇ Triphones (only CVC combinations in logatoms aprox. 6000 units) for covering all VC and CV spectral transitions. This corpus was intended primarily to prepare a classical diphone/triphone synthesis based on signal processing. ˇ Diphones in various phonetic contexts have been collected in order to define the appropriate segmental structure of synthetic speech (approx. 5000 units). The database contains several instances of each diphone, taken from different meaningful phrase contexts (phonetic, rhythmic, morphological) and therefore with different spectral features. The length of the phonetically rich phrases varied from three to six syllables to provide a complete segmental coverage of phonemes pairs, but not coverage of suprasegmental structures (the fundamental frequency of the recorded phrases varied from 95 Hz 110 Hz and can thus be considered stable).
Session 312: Communication Technologies for Disabled People
A Model for Sign Language Grammar, Boris Lenseigne / Patrice Dalle / France Sign language processing is often focused on individual sign processing which means that one needs an exhaustive description of those gestures. In this paper we propose a computational model of sign language utterances based on the construction of the signing space and a grammatical description: the iconicity theory. This model leads to an entity-and-relationship description of the meaning of the discourse which can be attached to a qualitative description of the gestures that where used to produce that utterance.
Automatic Recognition of Signed Polish Expressions / Tomasz Kapuscinski and Marian Wysocki / Poland The paper considers recognition of single sentences of the Polish Sign Language. We use a canonical stereo system that observes the signer from a frontal view. Feature vectors take into account information about the hand shape and 3D position of the hand with respect to the face. Recognition based on human skin detection and hidden Markov models (HMMs) is performed on line. We focus on 35 sentences and a 101 word vocabulary that can be used at the doctor's and at the post office. Details of the solution and results of experiments with regular and parallel HMMs are given. Keywords: gesture recognition, sign language, computer vision, hidden Markov models
DSP techniques for application to hearing aids / Adam Dąbrowski, Tomasz Marciniak and Paweł Pawłowski / Poland
Session 313: Natural Language Interfaces I
Using software agents to personalize natural-language access to Internet services in a chatterbot manner / Jarogniew Rykowski / Poland In this paper, a generic technology is proposed for developing personalized, chatterbot-like interfaces to network services. The technology is based on voice-based and textual access to services via user-defined software agents. Agent Computing Environment (ACE) is used as the main implementation framework. The agents are personalized by the users and specialized for the services the users are going to access. The way of using an agent may be also (automatically) adjusted to the hardware/software environment, communication link, possibilities of end-user devices, user preferences, etc.
FAQChat as an Information Retrieval System / Bayan Abu Shawar, Eric Atwell and Andrew Roberts / UK Human computer interfaces are created to facilitate communication between human and computers in a user friendly way. For instances information retrieval systems such as Google are used to remotely access and search a large information system based on keyword matching. However, the best interface is arguably one which fools you into thinking that you are speaking/asking a real human; a chatbot. A chatbot is a conversational software agent, which interacts with users using natural language. The idea of chatbot systems originated in the Massachusetts Institute of Technology, where Weizenbaum implemented the ELIZA chatbot to emulate a psychotherapist (Weizenbaum, 1966). After ELIZA, a lot of chatbots or human-computer dialogue systems have been developed either to simulate different fictional or real personalities such as PARRY (Colby, 1999) to simulate a paranoid patient, or to be used as an interface to help systems or web-based search engines such as AskJevees (2004). We have worked with the ALICE open-source chatbot initiative. ALICE (ALICE, 2002; Wallace, 2003) is the Artificial Linguistic Internet Computer Entity, developed by Wallace in 1995. In the ALICE architecture, the "chatbot engine" and the "language knowledge model" are clearly separated, so that alternative language knowledge models can be plugged and played. We have techniques for developing new language models, to chat around a specific topic: the techniques involve machine learning from a training corpus of dialogue transcripts, so the resulting chatbot chats in the style of the training corpus. User input is effectively used to search the training corpus for a nearest match, and the corresponding reply is output. We adapted this chatbot-training program to the FAQ in the School of Computing (SoC) at University of Leeds, producing the FAQchat system. The results returned from FAQchat are similar to ones generated by search engines such as Google, where the outcomes are links to exact or nearest match web pages. A search engine is "a program that searches documents for specific keywords and returns a list of the documents where the keywords were found." (Internet.com, 2004). However FAQchat could also give direct answers and the algorithm underlying each tool is different. Section 2 describes ALICE architecture. Section 3 presents a brief introduction about the previous work. To
An IVR Script Design using Forward Scenario Simulation and Event Analysis / Zulikha Jamaludin and Abdullah Embong / Malaysia This paper will put forward a study of an alternative technique for building a structured IVR script using Forward Scenario Simulation (FSS) and Event Analysis (EA). The aim of this research is to design a useful Malay IVR script, and also identify the problems that cause information hiding. Also, the compelling elements will be identified and included in TBUI design for IVR systems. The structured approach proposed for building a dialogue agent script is by event simulation, followed by interview based on an imaginary prototype, recording of the respondent responses, respondent scripts, and analysis of each script. The result of this study lists the heuristic processes that can be employed by the designer if an evaluation of the designed IVR script is required. The banking domain is used as the test platform since this sector has the biggest user of IVR systems in Malaysia.
10:55-13:00 Technical Sessions
Session 321: Language Resources and Tools: Language Tools
Resources and tools for electronic legal language documentation / Paola Mariani and Costanza Badii / Italy This paper deals with electronic tools and methodologies for the storage, analysis and study of legal language, in particular in its historic semantic evolution. The aim is to help users in the query of legal terms in archives containing a great many of lessical data. The last aim is to construct a Subject Index online of legal language.
Keyword
Lists as Language Resources and Tools / Wiesław Babik / Poland The subject matter of this presentation are collections of keywords (or keyword lists) which constitute vocabularies of keyword languages. The author's intention is to demonstrate how different such lexical resources are, as well as their functions in documentary information retrieval systems. The results of studies presented here have their justification, for example in a general application of keywords in the Internet search engines, especially in the WWW system (the keyword search function), and the need to identify new methods of data retrieval based on controlled vocabularies. NooJ's dictionaries / Max Silberztein / France NooJ is the new linguistic development environment developed by Max Silberztein. It has been designed to replace INTEX in the near future. NooJ has been rewritten from the ground up, with a new computer architecture and an innovative linguistic engine that makes it possible to build a new set of NLP applications. Among other novelties, NooJ's linguistic engine uses a new type of lexical data base, its dictionaries, that are an improvement upon the INTEX dual system of DELA dictionaries and Lexicon-Grammar tables.
Component based lingware development using the EJB Model and XML linguistic interface / Sonia Bouaziz, Bilel Gargouri and Mohamed Jmaiel / Tunisia In this paper, we apply the software technology of components for lingware development. The main purpose is to reduce the complexity of lingware development using a decomposition approach that promotes the reuse and the integration of lingware components developed in different contexts. We encapsulate the linguistic description used to link these components into XML interface. First, we suggest an abstract model for lingware development systems based on components. Second, we describe some lingware components that we developed using the EJB (Enterprise Java Beans) as a model for software components. Finally, in order to validate our approach, we develop two lingware systems by integrating lingware components.
UAM Text Tools - a text processing toolkit for Polish / Tomasz Obrębski and Michał Stolarski / Poland The paper presents a new language processing toolkit developed at Adam Mickiewicz University. Its functionality includes currently tokenization, lemmatization, spelling correction, guessing descriptions for unknown words and will be extended in near future. It is organized as a collection of command-line programs, each performing one operation. The components may be connected in various ways to provide various text processing services. Also new user-defined components may be easily incorporated into the system. The toolkit is destined for processing raw (not annotated) corpora of Polish text. It will be freely available for research and educational use.
Session 322: Formats of Lexical Data and Language Formalisms
Towards a Formalism for the Computational Morphology of Multi-Word Units / Agata Savary / France Multi-word units (MWUs) are linguistic objects placed on the frontier between morphology and syntax. A reliable computational treatment of their inflectional morphology requires a fine-grained grammar-based approach allowing a description of general largecoverage phenomena as well as of lexicalized counter-rules. We propose a formalism that answers these requirements. Due to a graphbased description and a simple unification algorithm it allows to compactly and exhaustively describe the inflection paradigm of a MWU in terms of its component words' morphology as well as of some regular-language patterns.
Transformation of WordNet Czech Valency Frames into Augmented VALLEX-1.0 Format / Dana Hlavackova and Aleš Horak / Czech Republic The paper presents details and comparison of two valuable language resources for Czech, two independent verb valency frames electronic dictionaries. The FIMU verb valency frames dictionary was designed during the EuroWordNet project and contains semantic roles and links to the Czech wordnet semantic network. The VALLEX 1.0 format is based on the formalism of the Functional Generative Description (FGD) and was developed during the Prague Dependency Treebank (PDT) project. We present the tools and approaches that were used within the process of adopting the FIMU Vallex format for the wordnet enriched valency frames.
XML-Based Representation Formats of Local Grammars for the NLP / Javier M. Sastre Martínez / France The construction of local grammars for the exact recognition of each valid structure of a natural language is a very long term task which consumes huge amounts of human resources and produces huge amounts of data to be accumulated over the years. The use of convenient computer assisted grammar construction (CAGC) tools alleviates this task, but the representation format of the generated data must not be tool-dependent because of two reasons: the data must persist across the time in spite of the short life span of such tools due to the fast computer technology evolution; cooperative work groups must be able to easily exchange their data even if they use different CAGC tools. We propose here two equivalent representation formats based in well-covered solid standards, like XML and XML-Schema, and conceived to serve as exchange formats between computer applications dealing with local grammars.
Lexicon management and standard formats / Eric Laporte / France International standards for lexicon formats are in preparation. To a certain extent, the proposed formats converge with prior results of standardization projects. However, their adequacy for (i) lexicon management and (ii) lexicon-driven applications have been little debated in the past, nor are they as a part of the present standardization effort. We examine these issues. IGM has developed XML formats compatible with the emerging international standards, and we report experimental results on large-coverage lexica.
A formal model of Polish nominal derivation / Joanna Rabiega-Wiśniewska / Poland In this paper, a formal description of Polish word formation (nouns in particular) is discussed. First, we introduce empirical data and list problems of derivational analysis that we take into consideration. In the next sections we present not only theoretical statements given in Polish literature but also findings of various computational works concerning other inflecting languages. Our aim is to present a formal approach to analysis (synthesis) of Polish derivatives that can be implemented as a computational application.
Reinterpreting DCG for free(r) word order languages / Zygmunt Vetulani and Filip Graliński / Poland The DCG rules are context-free rules with non-terminal symbols allowing arbitrary terms as parameters. Because of that the DCGlike formalisms are considered as particularly well suited to encode NL grammars. This observation is however only partially true for languages with free (or freer) word order (and possibilities of discontinuous constructions), as e.g. Slavonic and (some) Germanic languages. What seems interesting is that a minor formal modification in the DCG formalism makes it flexible enough to cover wordorder related problems. What we explore here is the idea of reinterpretation of the concept of difference list. This implies a nonstandard interpretation of the DCG rules, in which the ordering of the right-hand-side symbols does not correspond anymore to the surface (linear) ordering of corresponding expressions and the non-terminals may represent discontinuous categories.
Session 323: Parsing I
Across-Genres and Empirical Evaluation of State-of-the-Art Treebank-style Parsers / Vasile Rus and Christian F. Hempelmann / USA This paper evaluates a series of freely available, state-of-the-art parsers on a standard benchmark as well as with respect to a set of data important to measure text cohesion in the context of learning technology. We outline pros and cons of existing parsing technologies and make recommendations. The performance reported uses traditional measures as well as novel dimensions for parsing evaluation to develop a gold standard for narrative and expository texts. To our knowledge this is the first attempt to evaluate parsers accross genres.
Categorial grammar elements in the Thetos system's parser / Nina Suszczańska and Przemysław Szmal / Poland Thetos system enables translation of Polish texts into the Polish sign language. The parser used in Thetos is based on the Syntactic Group Grammar for Polish (SGGP). While parsing, it selects possible syntactic productions. Since this job cannot be done on the only basis of pure syntactic premises, the parser has to gather, process, and use semantic information. The information is held in attribute structures associated with individual symbols terminal and non-terminal of the utterance being processed. The structures and operations are in fact elements of categorial grammars. In the paper we show the form of attribute structures, basic operations on structures, selected attribute value sets, and sample semantic rules used to identify selected syntactic group types.
An efficient implementation of a large grammar of Polish / Marcin Woliński / Poland The paper presents a parser implementing Marek Swidziński's formal grammar of the Polish language. The grammar was written by n a linguist, without a computational implementation in mind, unlike most formal grammars. The aim of the work reported here is to examine what the exact set of sentences accepted by the grammar is and what structures are assigned to them. For that reason, it was crucial to remain as close to the original grammar as possible. The resulting program, named Swigra, goes far beyond a toy parser due to the use of a morphological analyser and a broad range of linguistic phenomena covered by Swidziński's grammar. In this article n preliminary results of the parser evaluation are also provided.
From raw corpus to word lattices: robust pre-parsing processing / Benoît Sagot and Pierre Boullier / France We present a robust full-featured architecture to preprocess text before parsing. It converts raw noisy corpus into a word lattice that will be used as input by a parser. It includes sequentially named-entity recognition, tokenization and sentence boundaries detection, lexicon-aware named-entity recognition, spelling correction, and non-deterministic multi-words processing, re-accentuation and de-/recapitalization. Though our system currently deals with French language, almost all components are in fact language-independent, and the others can be straightforwardly adapted to almost any inflectional language. The output is a lattice of words that are present in the lexicon. It has been applied on a large scale during a French parsing evaluation campaign, showing both extreme efficiency and very good precision and recall.
A pattern-classification based solution for the recognition of tense of the Chinese language / Lin Dazhen, Li Shaozi, Cao DongLin and Lin Ying / China As far as NLP is concerned, the tense of the Chinese language is especially hard to tackle. One of the outstanding characteristics of the Chinese language is that its tense is usually implied rather than obvious. Hence, the Rule-based solution is far from suitable for the recognition of tense in situations where tense-informing words are missing or more than one of such words are present. In this paper, we introduce a pattern-classification based solution, which evaluates each single word in terms of its contribution to the recognition of tense for the concerned sentence. This solution proves effective and efficient when processing sentences containing none or more than one tense-informing words. Furthermore, the implementation of linear discriminating function in this solution leads to its abilities of multi-dimensional data processing and training, and helps to achieve decent performance. Evaluated under open conditions, the Precision and Recall of this solution are 79% and 95.3%, respectively.
14:15-15:45 Technical Sessions
Session 331: Systems
Virtual Environment for Interactive Learning Languages / P.S.Pankov and E. Alimbay / Kyrgyzstan Software is proposed for learning any language without any other language being a medium. It is based on the principle of guessing and fulfilling the only natural action possible in the environment. At the first stage the pupil fulfills commands given by a loudspeaker (earphones) and duplicated in written form by a display. At the second stage the pupil gives commands by voice, the program tries to recognize and to fulfill them.
Language Archive Management and Upload System / Peter Wittenburg, Daan Broeder and Andreas Claus / Netherlands When a language archive reaches a certain size the need arises for an automated system to manage this archive. One way is to create a tool for the researchers which allows them to manage the content of the archive themselves. Such a system should guide the researchers and allow them to insert new data and delete or change existing data. At the Max Planck Institute for Psycholinguistics we are developing software which fulfills these requirements on the basis of the IMDI Metadata framework. The requirements and possibilities of such a system are discussed in this document.
Advanced Web-based Language Archive Exploitation and Enrichment / Peter Wittenburg, Albert Russel, Peter Berck and Marc Kemps-Snijders / Netherlands This article describes the linguistic archive set up at the MPI in Nijmegen. The MPI is in the progress of making it possible to exploit and enrich this archive over the internet with standard tools like a webbrowser. We describe how the different parts that make up the archive work together and the current state of the web based exploration. We also show the future direction for each of the different parts.
Session 341a: Language Resources and Tools: AI Derived Methods
A Lemmatization Web Service Based on Machine Learning Techniques / Joel Plisson, Dunja Mladenic, Nada Lavrac and Tomaž Erjavec / Slovenia Lemmatization is the process of finding the normalized form of words from surface word-forms as they appear in the running text. It is a useful pre-processing step for any number of language engineering tasks, especially important for languages with rich inflection morphology. This paper presents two approaches to automated word lemmatization, which both use machine learning techniques to learn particular language models from pre-annotated data. One approach is based on Ripple Down Rules and the other on First-Order Decision Lists. We have tested the two approaches on the Slovene language and set-up a generally accessible Web service for lemmatization using the generated models.
Session 332: Natural Language Interfaces II
FAQFinder Question Answering Improvements Using Question/Answer Matching / Stanley J. Mlynarczyk and Steven L. Lytinen / USA FAQFinder is a tool that was developed to provide answers to user questions through the retrieval of previously asked questions residing in Internet Frequently Asked Questions (FAQ) files, primarily USENET FAQ files. Instead of generating responses to a user question from scratch, the FAQFinder approach is to analyze a user's natural language query and to use this analysis to find a similar question that has been asked and answered previously. Our approach is to use a variety of techniques from information retrieval and natural language processing to match user questions with similar questions in FAQ files.
Designing a Universal Interfacing Agent / Darsana P. Josyula, Michael L Anderson and Don Perlis / USA This paper argues the need for a universal interfacing agent that users can use to control different task-oriented systems. It discusses the different capabilities required of such an agent and what is required for implementing those capabilities. In addition, it provides an approach for its implementation
Lingubot for the Library - initial case study / Piotr Malak / Poland Lingubots, artificial intelligence tools, serve as virtual, natural language communication supporting web assistants. The software is already being used by some leading commercial or financial institutions worldwide. Analyses prove its positive influence for the institutions, both in the meaning of costs saving and in customer satisfaction increase. The 24/7/365 work model and simultaneous sessions handling with no loss of quality result in decrease of help desks or call centers workload together with high level of customer service quality maintaining all the time, any time. Quick, coherent customer question answering cause up to 10% of customer satisfaction increase. Lingubots have proven it usefulness, and seems to be very good solution in any user help or guidance system. Present paper describes development of lingubot for Nicolas Copernicus University Main Library. Initial assumptions, fields of application and used techniques are discussed.
Session 342a: Multilingual Applications
An Intelligent, Context-Sensitive Dictionary: A Polish−English Comprehension Tool / Gábor Prószéky and András Földes / Hungary This paper introduces an EnglishPolish and PolishEnglish electronic dictionary sensitive to the context of the input words or expressions. The dictionary program provides translations for any piece of text displayed on a computer screen without requiring user interaction. This functionality is provided by a three-layer process: (1) text acquisition from the screen, (2) morpho-syntactic analysis of the context of the selected word and (3) the dictionary lookup. By dividing dictionary entries into smaller pieces and indexing them individually, the program is able to display a restricted set of information that is as relevant to the context as possible. For this purpose, we utilize automatic and semi-automatic XML tools for processing dictionary content. The construction of such an electronic dictionary involves natural language processing at almost every point of operation. Both dictionary entries and user input require linguistic analysis and intelligent pattern-matching techniques in order to identify multi-word expressions in the context of the input. An on-going research makes the program incorporate more sophisticated language technology: multi-word phrases and sentences are recognized, and translation hints are offered in an intelligent way by a parser/transformer module matching underspecified patterns of different degrees of abstraction.
Session 333: Text generation & Knowledge Representation
Temporal Reasoning in Propositional Interval Neighborhood Logic / Guido Sciavicco / Italy Interval-based temporal reasoning is an important field of various areas of Computer Science and Artificial Intelligence, such as planning and natural language processing. In this paper we show that the satisfiability problem for one of the most important formalisms for interval-based reasoning, namely Allen's Interval Algebra, can be reduced to the satisfiability problem for Propositional Neighborhood Logic.
Compositional, Variable Free, Binding Free and Structure Oriented Discourse Interpretation / Maciej Piasecki / Poland Our main objective will be to construct a fully compositional representation of nominal anaphora in discourse. The proposed representation is not dependent on the remote ascription (i.e. done outside the formal representation) of syntactic indexes, which identify anaphoric links. A formal language of variable free logic is introduced. It is based on dynamic semantics paradigm and is a variant of many-sorted type logic. We will also present the scope free treatment of quantification in multiple quantifier sentences. The interpretation of multiple quantifiers is defined by means of a construction of the polyadic Generalised Quantifier (GQ). The polyadic GQ is a constraint that should be satisfied by the denotation of a `clausal' predicate.
Perspective and Aspect in Narrative Generation / Greg Lessard and Michael Levison / Canada The generation of narrative texts poses particular difficulties with respect to the interplay of description and narration, the recounting and interpretation of events from different perspectives, and the interweaving of dialogue and narration. Starting from previous work within the VINCI natural language generation environment, we show how a model of perspective and aspect proposed in the 1960's by the linguist Andr´ Burger allows for a significant enrichment of generated narratives in these three respects.
An empirical approach toward building a soccer commentary generator / Damian Stolarski / Poland This paper presents issues associated with the project of building a soccer commentary system for RoboCup environment. The proposed approach uses fragments of real commentary as a basis for the project. The paper specifies tasks necessary for the realisation of the system and demonstrates how the survey of examples could be helpful in generator building.
16:15-18:00 Technical Sessions
Session 341b: Language Resources and Tools: AI Derived Methods
A Multi-Agent System for Detecting and Correcting "Hidden" Spelling Errors in Arabic Texts / Chiraz Ben Othmane Zribi, Fériel Ben Fraj and Mohammed Ben Ahmed / Tunisia In this paper, we address the problem of detecting and correcting hidden spelling errors in Arabic texts. Hidden spelling errors are morphologically valid words and therefore they cannot be detected or corrected by conventional spell checking programs. In the work presented here, we investigate this kind of errors as they relate to the Arabic language. We start by proposing a classification of these errors in two main categories: syntactic and semantic, then we present our multi-agent system for hidden spelling errors detection and correction. The multi-agent architecture is justified by the need for collaboration, parallelism and competition, in addition to the need for information exchange between the different analysis phases. Finally, we describe the testing framework used to evaluate the system implemented.
Part-of-Speech tagging based on artificial neural networks / Salvador Tortajada Velert, María José Castro Bleda and Ferran Pla Santamaría / Spain In this paper, we describe a Part-of-Speech tagging system based on connectionist models. A Multilayer Perceptron is used following corpus-based learning from contextual and lexical information. The Spanish corpus LexEsp has been used for the training and evaluation of the tagging system based on artificial neural networks. Different approaches have been compared and results with the Hidden Markov Model systems are also given. The results show that the connectionist approach is feasible.
On-Line Learning with Rule Base Expert System: Implemented In RoboCup Soccer Coach Simulation / Ramin Fathzadeh, Vahid Mokhtari, Mohammad Reza Shoaei, Morteza Mousakhani, Alireza Mohammad Shahri and Reza Fathzadeh / Iran In this paper we will describe our research in case of using Expert System as a decision-making system. We made our attempt to implement an online learning system which receives information from the environment. In developing the coach, the main research effort comprises two complementary parts: (a) Design a rule-based expert system in which its task is to analyze the game (b) Employing the decision-making trees for generating advice. Considering these two methods, coach learns to predict agent behavior and automatically generates advice to improve team's performance. This structure is tested previously in RoboCup Soccer Coach Simulation League. Using this approach, the MRLCoach2004 took first place in the competition held in 2004. Keywords: Rule Base Expert System, Decision-Making Tree, RoboCup, CLang
Learning Context-Free Language using Grammar-based Classifier System / Olgierd Unold / Poland Grammar-based classifier system (GCS) is a new version of Learning Classifier Systems (LCS) in which classifiers are represented by context-free grammar in Chomsky Normal Form. GCS works basically like all other LCS models but it differs from them (i) in the covering, (ii) in the matching, and (iii) in representation. We modify the discovering component of the GCS and apply system for inferring such context-free languages as toy language, and grammar for large corpora of part-of-speech tagged natural English language. For each task a set of experiments was performed.
Transformation Based Learning Applied to Noun Phrase Extraction of Brazilian Portuguese Texts: Language-specific Issues / Cicero Nogueira dos Santos and Claudia Oliveira / Brasil This paper describes a Transformation Based Learning (TBL) noun phrase extractor for Portuguese. We discuss the reasons for variation in performance between experiments with Portuguese and with English, taking special notice of the linguistic differences between the two languages with respect to noun phrases. Latin languages such as Spanish, French and Italian will present the same problems, and could benefit from the same analysis presented here.
Session 342b: Multilingual Applications
Translation of Sentences by Analogy Principle / Yves Lepage / Japan This paper presents a machine translation method based on the analogy principle, and an experiment in translation as well as its objective evaluation. The first part of the paper restates and generalizes the original proposed framework called "translation by analogy principle". The second part of the paper builds on the recent development of linguistic resources, specifically bicorpora, and reports on an experiment in translation using the method, its objective evaluation, as well as a comparison with other systems. The third part comments on the characteristics of the method and puts it into a more linguistic perspective.
A Conceptual Ontology for Machine Translation from/into Polish / Krzysztof Jassem and Agnieszka Wagner / Poland The paper presents a conceptual ontology that has been developed for the purpose of machine translation from and into Polish. The ontology has been applied in Translatica a general domain MT system that currently translates texts between Polish and English and aims at the development of other language pairs including Polish. The Translatica ontology, designed mainly for disambiguation purposes, contains noun terms. The ontological concepts are applied as semantic values in lexical rules for verbs, adjectives and prepositions. The ontology is based on WordNet. The paper compares the adopted approach to those used in other transfer-based and interlingua-based systems. It also points out and justifies the differences between the Translatica ontology and WordNet.
Template-Based Shake & Bake Paraphrasing / Michael Carl, Ecaterina Rascu and Paul Schmidt / Germany In this paper we propose an approach to corpus-based generation in a machine translation framework that is similar to shake & bake. Target language sentences are generated by mapping items in the target language bag against an automatically induced template grammar. Within this approach, paraphrasing is used both as a verifying instrument and a means to improve the performance of the system.
Towards Development of Multilingual Spoken Dialogue Systems / Hartwig Holzapfel / Germany Developing multilingual dialogue systems brings up various challenges. Among them development of natural language understanding and generation components, with a focus on creating new language parts as rapidly as possible. Another challenge is to ensure compatibility between the different language specific components during maintenance and ongoing development of the system. We describe our experiences with designing multilingual dialogue systems and present methods for multilingual grammar specification, as well as development and maintenance methods for multilingual grammars used for language understanding, and multilingual generation templates. We introduce grammar interfaces, similar to interface concepts known from object oriented languages, to improve compatibility between different grammar parts and to simplify grammar development.
Towards Automatic Translation of Support Verbs Constructions: the Case of Polish robić/zrobić and Swedish göra / Elżbieta Dura and Barbara Gawrońska / Sweden Support verb constructions range from idiosyncratic to predictable. Lexical functions provide a solution to translation of idiosyncratic constructions only. Our corpus research aims to contribute to automatic translation of support verb constructions where the verb selects certain semantic groups of collocates, and where novel collocations can be expected. We investigate samples of support verb constructions with Polish robi/zrobi and Swedish göra. Nouns attested on the Internet as objects of these verbs are subdivided into semantic groups. Translation rules are then proposed for each group, and the similarities and differences in the behaviour of the verbs in both languages are discussed.
Session 343: Parsing II
A Chinese Top-down Parser Based on Probabilistic Context Free Grammar / Ying Lin, Xiaodong Shi, Feng Guo and Dazhen Lin / China This paper studies the limitations of A PCFG, and then presents a definition of syntax structural co-occurrence and its computational method. In order to break up the limitation of the Chinese Treebank scales, the paper presents an improved Inside-Outside algorithm to obtain the arguments of syntactic rules. In the end, the paper presents a Probabilistic Top-Down Parser. Experiments show that this method can get a good performance of the label precision rates and label recall rates.
Memory-based PP Attachment Disambiguation for Norwegian / Anders Nøklestad / Norway Determining the correct attachment site for prepositional phrases is a difficult task for NLP systems. In this work we automatically extract unambiguous PP attachments from a Norwegian corpus and use them for semi-unsupervised training of a memory-based learner on the attachment disambiguation task. The performance of the system is similar to that of a related method which has previously been applied to English. We discuss probable reasons for performance differences between this system and other semi-unsupervised systems for English.
Parsing Texts Written in Natural Language with CBR / Robert Papis and Przemysław Nowak / Poland This paper presents a novel method for parsing sentences written in natural language that utilizes case-based reasoning approach. Thc case representation is designed in such a way that the case refers not to the whole sentence, but only to one relation between its words. Therefore the relations can be first identified individually and then together give rise to a parse graph. Their identification is carried out on the basis of morphosyntactic information as no semantics is taken into account. A preliminary evaluation study proves that the method is promising.
Semantics Parsing Revisited or How a Tadpole Could Turn into a Frog / Wai-Kiang Yeap / New Zealand Early AI researchers got it right; that language is about semantics parsing. However, instead of focusing on developing the necessary framework to support semantics parsing, these researchers have focused mainly on how word meanings are represented and used. In this paper we developed one such framework and argued that it provides a more natural explanation as to how children might acquire their first language. A LISP program has been implemented to test the idea developed.
Can we parse without tagging? / Patrick Watrin, Sebastien Paumier and Cédrick Fairon / Belgium Syntactic parsing is a major area of NLP which has been widely studied with the help of many approaches. Usually, parsers take in input tagged texts, that is to say texts whose lexical units have been annotated with informations such as lemma, grammatical code, gender and number. In this paper, we present a parsing method that can work on untagged texts as well as on tagged ones. We then compare results obtained on specialized texts in their raw and tagged version in order to determine if tagging is absolutely necessary. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Two additional sessions are planned:
For "Demo session" a stand for participant's computer equipement will be provided. The pesenter(s) may also prepare a poster with a short information about the demo. Requirements:
All questions should be addressed to one of the session chairs. Session chairs: Jacek Marciniak (jacekmar@amu.edu.pl) and Tomasz Obrebski (obrebski@amu.edu.pl) |
 |
|
|
|
|
|


|
 |

