Submissions from (until now):






































Submissions from (until now):
|
Photo Gallery |
|
|
|
as a Challenge for Computer Science and Linguistics |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
       
 |
 |
 |
|
Collegium Minus, Presidence |
and Computer Science |
|
|
























































































































|
|
|
|
Dear Colleagues, The 4th Language and Technology Conference (LTC'09), a meeting organized by the Faculty of Mathematics and Computer Science of Adam Mickiewicz University, Poznań, Poland in cooperation with the Adam Mickiewicz University Foundation (co-organizer), will take place on November 6-8, 2009. Human Language Technologies (HLT) continue to be a challenge for computer science, linguistics and related fields as these areas become an ever more essential element of our everyday technological environment. Since the very beginning of the Computer and Information Age these fields have influenced and stimulated each other. The European Union strongly supports HLT under the 7th Framework Program. These efforts as well as technological, social and cultural globalization have created a favorable climate for the intensive exchange of novel ideas, concepts and solutions across initially distant disciplines. We aim at further contributing to this exchange and invite you to join us at LTC in November 6-8, 2009 as well as at the satellite FlaReNet workshop (November 6) co-located with the LTC'09. This event is listed at the Computer Science Event List, www.informatics-europe.org
Zygmunt Vetulani |
|
|
|
The conference topics include the following (the ordering is not significative):
This list is by no means closed and we are open to further proposals. Please do not hesitate to contact us in order to feed us with you suggestions and ideas of how to satisfy your expectation concerning the program. The Program Committee is also open to suggestions concerning accompanying events (workshops, exhibits, panels, etc). Suggestions, ideas and observations may be addressed directly to the LTC Chair by email (vetulani@amu.edu.pl). |
|
|
| Zygmunt Vetulani (Adam Mickiewicz University, Poznań, Poland) - chair |
| Victoria Arranz (ELRA, France) |
| Anja Belz (University of Brighton, UK) |
| Janusz S. Bień (Warsaw University, Poland) |
| Krzysztof Bogacki (Warsaw University, Poland) |
| Christian Boitet (IMAG, France) |
| Leonard Bolc (IPI PAN, Poland) |
| Lynne Bowker (University of Ottawa, Canada) |
| Nicoletta Calzolari (ILC/CNR, Italy) |
| Nick Campbell (Trinity College Dublin, Ireland) |
| Julie Carson-Berndsen (University College Dublin, Ireland) |
| Khalid Choukri (ELRA, France) |
| Adam Dąbrowski (Poznań University of Technology, Poland) |
| Elżbieta Dura (University of Skovde, Sweden) |
| Katarzyna Dziubalska-Kołaczyk (Adam Mickiewicz University, Poznań, Poland) |
| Tomaz Erjavec (Josef Stefan Institute, Slovenia) |
| Cedrick Fairon (University of Louvain, Belgium) |
| Christiane Fellbaum (Princeton University, USA) |
| Maria Gavrilidou (ILSP, Greece) |
| Dafydd Gibbon (University of Bielefeld, Germany) |
| Stefan Grocholewski (Poznań University of Technology, Poland) |
| Franz Guenthner (Ludwig-Maximilians-University München, Germany) |
| Hans Guesgen (Massey University, New Zealand) |
| Eva Hajičová (Charles University, Czech Republic) |
| Roland Hausser (Erlangen, Germany) |
| Steven Krauwer (University of Utrecht, Netherlands) |
| Eric Laporte (University Marne-la-Vallee, France) |
| Yves Lepage (University Caen Basse-Normandie, France) |
| Gerard Ligozat (LIMSI/CNRS, France) |
| Natalia Loukachevitch (Research Computing Center of Moscow State University, Russia) |
| Wiesław Lubaszewski (AGH/UJ, Poland) |
| Bente Maegaard (Centre for Language Technology, Denmark) |
| Bernardo Magnini (ITC IRST, Italy) |
| Joseph Mariani (LIMSI-CNRS, France) |
| Jacek Martinek (Poznań University of Technology, Poland) |
| Gayrat Matlatipov (Urgench State University,Uzbekistan) |
| Keith J. Miller (MITRE, USA) |
| Nicholas Ostler (Linguacubun Ltd., UK) |
| Karel Pala (Masaryk University, Czech Republic) |
| Pavel S. Pankov (National Academy of Sciences, Kyrgyzstan) |
| Patrick Paroubek (LIMSI-CNRS, France) |
| Stelios Piperidis (ILSP, Greece) |
| Emil Pływaczewski (University of Bialystok, Poland) |
| Gabor Proszeky (Morphologic, Hungary) |
| Adam Przepiórkowski (IPI PAN, Poland) |
| Reinhard Rapp (University Mainz, Germany) |
| Zbigniew Rau (PPBW, Poland) |
| Mike Rosner (University of Malta) |
| Justus Roux (University of Stellenbosch, South Africa) |
| Vasile Rus (University of Memphis, Fedex Inst. of Technology, USA) |
| Rafał Rzepka (University of Hokkaido, Japan) |
| Frédérique Ségond (Xerox, France) |
| Zhongzhi Shi (Institute of Computing Technology / Chinese Academy of Sciences, China) |
| Włodzimierz Sobkowiak (Adam Mickiewicz University, Poznań, Poland) |
| Hanna Szafrańska (UAM Foundation, Poland) |
| Marek Świdziński (University of Warsaw, Poland) |
| Ryszard Tadeusiewicz (AGH, Poland) |
| Dan Tufiş (RCAI, Romania) |
| Hans Uszkoreit (DFKI, Germany) |
| Piek Vossen (University of Amsterdam, Netherlands) |
| Tom Wachtel (Independent Consultant, Italy) |
| Jan Węglarz (Poznań University of Technology, Poland) |
| Mariusz Ziółko (AGH, Poland) |
| Richard Zuber (CNRS, France) |
|
|
| Zygmunt Vetulani - Chair |
| Marek Kubis |
| Piotr Kuszyk - secretary |
| Jacek Marciniak |
| Tomasz Obrębski |
| Jędrzej Osiński |
| Justyna Walkowska |
| All of Adam Mickiewicz University, Poznań, Poland |
| Contact: ltc@amu.edu.pl |
|
|
|
The conference language is English. |
|
|
|
Closed. |
|
|
|
Final papers are due by October 12, 2009. We strongly recommend using the templates for MS Word. In any case, please do observe the following:
Final papers should be sent by e-mail to ltc@amu.edu.pl as an attachment. A security copy should be sent to vetulani@amu.edu.pl.
The PAPERID is your paper ID from EasyChair. |
|
|
|
Acceptance will be based on the reviewers' assessments (anonymous submission model). The accepted papers will be published in the conference proceedings (hard copy, with ISBN number) and on CD-ROM. The abstracts of the accepted contributions will also be made available via the conference page (during its lifetime). Publication requires full electronic registration and payment of the conference fee (full registration) by at least one of the co-authors by October 12, 2009. (In case of more than one accepted paper a special regulation will be applied. This regulation will be announced later on.) A post-conference volume with extended versions of selected papers will be published. It is planed to publish them in the Springer series Lecture Notes in Artificial Intelligence (final approval pending). The LTC 2005 post conference selection appeared in form of Special Issue of Archives of Control Sciences (2005, Volume 15 nb. 3 and Volume 15 nb. 4) |


|
|
The LTC 2007 post-conference volume (revised, extended papers) has just appeared in the Springer Verlag series LNAI (vol. 5603). |
 |
|
|
*) We will do our best to communicate our decision as soon as possible after the sumbission, in order to give the Authors time to make their travel arrangements. |
|
|
|
Only electronic registration is possible. |
|
|
|
Non-student participants:
Student registrations must be accompanied by a proof of full-time student status valid on the payment date. Registrants are requested to scan and e-mail their proof of student status to ltc@amu.edu.pl. The e-mail subject field must have the following format: The conference fee covers:
|
|
|
By credit card (recommended): Please do follow the following 5-step procedure:
Important: if payment by bank transfer, all transfer fees must be covered by the participant. Important: make sure you have included the name of the conference and your family name as part of the payment reference. |
|
|
|
Name: Getting Less-Resourced Languages on-Board! (New) Date: 6.11.2009, half-day (afternoon) + banquet Theme: Language Technologies (LT) provide an essential support to the challenge of Multilingualism. In order to develop them, it is necessary to have access to Language Resources (LR) and to assess LT performances. To this regard, the situation is very different across the different languages. Little or sparse data exist for languages in countries or regions where limited efforts have been devoted to such issues in the past, also known as Less-Resourced Languages (LRL). The workshop aims at reporting the needs, at presenting achievements and at proposing solutions for the future, both in terms of LR and of LT evaluation, especially in the European, Euro-Mediterranean and regional frameworks. This will allow to identity the factors that have an impact on a potential and shared roadmap towards supplying LR and LT for all languages. Topics:
Co-Chairs: Joseph Mariani (LIMSI-CNRS & IMMI-CNRS), Khalid Choukri(ELRA & ELDA), Zygmunt Vetulani (Adam Mickiewicz University, Poznan) LRL Workshop Program Committee :
Paper submission deadline: September 6. Sponsors: FLaReNet, ELRA Inscriptions: as for the general LTC (+ cc to workshop chairs) Fees: free for LTC registered participants; 80 Euros for the Workshop-only attenders Paper submission: as for the general LTC (EasyChair) + to the workshop chairs (EasyChair)Presentation: publication in the LTC proceedings (paper + CD) Reviewing: up to the workshop chairs + Program Committee Program: The workshop will comprise presentations (including keynote talks) and a panel session, including a EC representative (tentative). In addition, selected speakers will be invited to present their papers to a larger audience at the main LTC conference. |
|
|
|
Key issue: "How to make standards attractive = how to make attractive standards?" Organisers: CLARIN, FLaReNet Moderator: Steven Krauwer (CLARIN/ELSNET/UiL OTS) Inved panelists : to be confirmed Objectives: A precondition for standards to be attractive seems meeting real needs of the community of users. Identification of needs is therefore essential and improving methodologies which would permit doing it correctly is an important challenge. This is also an urgent task regarding the globalisation pressure and the risk of growing technological gap between the so called "Less-resourced languages" and technologically leading ones. The panel is intended to be a contribution to face this challenge. Planned date: 7.11.2009, afternoon |
|
|
|
Objectives:The aim of the ITPS Special Track is an overview of the results obtain within three years research-and-development projects of PPBW, as well as confrontation of the results obtain so far with the initial expectations and the newly manifested needs. This Special Track aims at detection of new application areas of Language Technologies in the field of Public Security. Key words: Homeland security, Human language technologies, Systems with natural language competence, Language engineering resources for the security domain, Speech and text processing, Multilingual aspects, Legal aspects of human language technologies of security domain Organisers: PPBW - Polish Platform for Homeland Security Chairs: Dr. Zbigniew Rau (PPBW), Prof. dr. Emil W. Pływaczewski (Univ. Białystok) Secretary: Rashel Talukder(PPBW) Contributors : invited representatives of the PPBW projects and external presenters Participants : the ITPS is an integral part of the LTC and is open to all LTC participants Submissions : the external presenters are supposed to follow the same procedure as for the LTC, additionally, they are requested to send a security copy to Rashel Talukder and Zygmunt Vetulani by September 6 (with "LTC-ITPS Workshop" in the "subject" field); in particular, both invited and external presenters should submit papers using the EasyChair system (accessible via www.ltc.amu.edu.pl) Publications : as for LTC Planned date: 6.11.2009, afternoon Planned: individual presentations and a panel discussion (details available soon) |
|
|
|
Joint LTC-FLaReNet Satellite Workshop (LRL 2009) : Getting Less-Ressourced Languages on Board! Special Track on Information Technologies in application to the Public Security Research Hyde Park Corner We will arrange "A Hyde Park style Speakers' Corner" for non-reviewed presentations and positions. A limited number of presentations (depending on the available space) will be accepted. The content must meet the conference scope and aims. Both form and content must conform to Polish and International Law. Texts will be presented on the sole responsibility of the authors/presenters and will not be published or reproduced in the Conference documents. Book exhibition (call for exhibitors in preparation). Authors are invited to bring hard copies of their papers and books. We plan to make special presentations of the achievements of the conference participants, irrespective of whether they are directly related to the conference topic. Other special events. Besides the standard conference presentation of papers, the Organizers are open to various kinds of initiatives (expos, demos, satellite workshops, panels, awards). A program of special events is now under construction. You are welcome to contact us with your suggestions. |
|
|
|
The 4th Language & Technology Conference will be held in the Poznań International Fair Conference Center (Głogowska 14), pavilion 14B (see the International Fair map). |
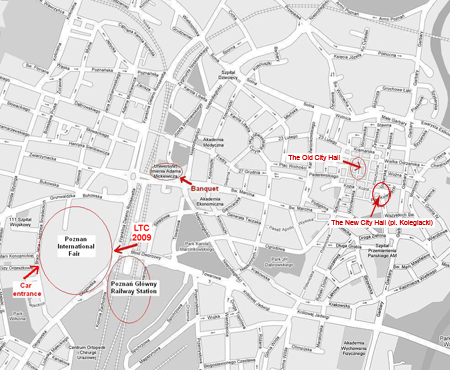
|
| See bigger map |
| Interactive Poznań map/street finder (Polish) |
|
|
|
Conference guest traveling by car may park them in the grounds of Poznań International Fair. To obtain a special PARKING PASS LTC'09', please send an e-mail to ltc@amu.edu.pl, giving "PARKING PASS LTC09" as the title. All cars have to use the Western Entrance in Śniadeckich street (see the International Fair map). |
|
|
| Day 1. Friday, 6.11 | |||||||||||||||||
| 8:00 - 9:30 | Registration | ||||||||||||||||
| 9:30 - 9:50 | Conference Opening | ||||||||||||||||
| 9:50 - 10:00 | Invited Talk Part 1 "New start for European language technology. Are you ready?" (Aleksandra Wesołowska, European Commission, Luxembourg) | ||||||||||||||||
| 10:00 - 10:30 | Coffee Break | ||||||||||||||||
| 10:30 - 12:10 | Speech 1 | Understanding | Parsing | ||||||||||||||
| 12:10 - 13:30 | Lunch Break | ||||||||||||||||
"Information Technologies in application to the Public Security Research"
|
"Getting Less-Resourced Languages on-Board!" |
||||||||||||||||
|
|
||||||||||||||||
| 15:30 - 15:35 | Conference photo | ||||||||||||||||
| 15:35 - 16:00 | Coffee Break | ||||||||||||||||
|
|
||||||||||||||||
| 20:00 - 0:00 | Conference banquet | ||||||||||||||||
| Day 2. Saturday, 7.11 | |||
| 8:30 - 10:10 | Word Sense disambiguation (Gardent Clair) |
Verb Valency (Marciniak Małgorzata) |
Information retrival / Information extraction 1 (Dura Elżbieta) |
| 10:10 - 10:40 | Coffee Break | ||
| 10:40 - 11:40 | Text annotation 1 (Dyczkowski Krzysztof) |
Corpora Building (Fukumoto Fumiyo) |
Machine Translation 1 (Jassem Krzysztof) |
| 11:40 - 11:45 | Technical Break | ||
| 11:45 - 12:45 | Text annotation 2 (Lepage Ives) |
Computational Semantics 1 (Marciniak Jacek) |
Lexicons (Richeus) |
| 12:45 - 14:00 | Lunch Break | ||
| 14:00 - 15:30 | Speech 2 (Pellegrini Thomas) |
Computational Semantics 2 (Paroubek Patrick) |
Summarization / Text Generation (Palotta Vincenzo) |
| 15:30 - 15:50 | Coffee Break | ||
| 15:50 - 16:50 | Panel discussion "How to make standards attractive = how to make attractive standards?" (Steven Krauwer, CLARIN/ELSNET/UiL OTS) | ||
| 16:50 - 18:15 | Tramway sightseeing (including transfer to the New City Hall) | ||
| 18:15 - 19:45 | Reception in the New City Hall (Plac Kolegiacki) by Mr Ryszard Grobelny, Mayor of Poznań | ||
| Day 3. Sunday, 8.11 | |||
| 9:00 - 9:30 | Invited Talk "CLARIN: Where we stand and where we are moving (Steven Krauwer, Utrecht institute of Linguistics UiL-OTS) | ||
| 9:30 - 9:35 | Technical Break | ||
| 9:35 - 10:35 | Speech 3 (Yeh Jui-Feng) |
Text analysis 1 (Dyachenko Pavel) |
Terminology (Kemps-Snijders Mark Robert Valentin) |
| 10:35 - 11:05 | Coffee Break | ||
| 11:05 - 12:45 | Ontologies / Wordnet (Pala Kiran) |
Computational Morphology (HolBrook Dwight) |
Information retrival / Information extraction 2 (Kettunen Kimmo) |
| 12:45 - 13:45 | Lunch Break | ||
| 13:45 - 15:15 | Language Teaching (Sarasola Kepa) |
Text analysis 2 (Savary Agata) |
Machine Translation 2 (Samsudin Nur Hana) |
| 15:15 - 15:40 | Coffee Break | ||
| 15:40 - 16:00 | Closure Session | ||
|
|
| Day 1, Friday, 6.11 | |||
| Speech 1 | |||
| SP1-1 | 82 | Robust Speech Recognition In The Car Environment | Agnieszka Betkowska Cavalcante, Koichi Shinoda, and Sadaoki Furui |
| SP1-2 | 49 | Automatic Processing of Disfluencies in Linguistically Constrained Spoken Dialogs | Jean-Leon Bouraoui, Nadine Vigouroux |
| SP1-3 | 71 | Error detection in automatic transcriptions using Hidden Markov Models | Thomas Pellegrini, Isabel Trancoso |
| SP1-4 | 72 | Impact of MRI scanner noise on Speech Recognition confidence score | Theologos Athanaselis, Stelios Bakamidis, Ioannis Dologlou, Evita Fotinea |
| SP1-5 | 1 | Time Durations of Phonemes in the Polish Language | Bartosz Ziólko and Mariusz Ziólko |
| Understanding | |||
| UN-1 | 15 | Abstractive Summarization of Voice Communications | Vincenzo Pallotta, Rodolfo Delmonte, Antonella Bristot |
| UN-2 | 20 | Question Answering Based on Semantic Graphs | Lorand Dali, Delia Rusu, Blaz Fortuna, Dunja Mladenic, Marko Grobelnik |
| UN-3 | 55 | Dialogue Organization in Polint-112-SMS | Justyna Walkowska |
| UN-4 | 66 | Boosting a Chatterbot Understanding with a Weighted Filtered-Popping Network Parser | Javier M. Sastre-Martinez, Jorge Sastre, Javier Garcia-Puga |
| UN-5 | 112 | Natural Language Based Communication Between Human Users and Emergency Center in Critical Situations. A Short-Text-Message Based Decision Assisting System POLINT-112-SMS | Zygmunt Vetulani |
| Parsing | |||
| PAR-1 | 3 | Defining the chunk as the period of the functions length and frequency of words on the syntagmatic axis | Jacques Vergne |
| PAR-2 | 64 | A Computational Analysis of Turkish in the Principles and Parameters Framework | Aysenur Birturk, Sandiway Fong |
| PAR-3 | 104 | Parsing CFGs and PCFGs with a Chomsky-Schutzenberger representation | Mans Hulden |
| PAR-4 | 114 | Syntactic Analysis as Pattern Matching: The SET Parsing System | Vojtech Kovar, Ales Horak and Milos Jakubicek |
| "Getting Less-Resourced Languages on-Board!" Technical Papers (session 1) | |||
| LRL ST1-1 | 52 | Design of an Efficient Corpus for High-Quality Unit Selection TTS for Bulgarian | Aimilios Chalamandaris, Pirros Tsiakoulis, Spyros Raptis, Sotiris Karabetsos |
| LRL ST1-2 | 122 | Speech synthesis as a first step towards speech technologies in Romani | Milan Rusko, Sakhia Darjaa, Marian Trnka |
| LRL ST1-3 | 12 | Morpheme-Based Language Modeling for Amharic Speech Recognition | Martha Yifiru Tachbelie, Solomon Teferra Abate, Wolfgang Menzel |
| LRL ST1-4 | 109 | Pronunciation and Writing Variants in Luxembourgish: The Case of Mobile N-Deletion in Large Corpora | Natalie D. Snoeren and Martine Adda-Decker |
| "Getting Less-Resourced Languages on-Board!" Technical Papers (session 2) | |||
| LRL ST2-1 | 57 | Valuable Language Resources and Applications Supporting the Use of Basque | Inaki Alegria, Maxux Aranzabe, Xabier Arregi, Xabier Artola, Arantza Diaz de Ilarraza, Aingeru Mayor and Kepa Sarasola |
| LRL ST2-2 | 22 | An experience on statistical machine translation between Spanish and the regional languages of Spain | Mireia Farrus, Gonzalo Iglesias, Carlos Henriquez, Marc Poch, Roberto Munoz, Nerea Ezeiza, Eduardo R. Banga, Jose B. Marino |
| LRL ST2-3 | 97 | Interlinear Glossing OnLine | Dorothee Beermann and Pavel Mihaylov |
| LRL ST2-4 | 98 | A methodology for enhancing argument structure specification | Lars Hellan, Mary Esther, Kropp Dakubu |
| "Information Technologies in application to the Public Security Research" Technical Papers (session 1) | |||
| PPBW ST1-1 | 126 | Database with facilities for speaker classification and recognition based on emergency telephone conversations | Adam Dabrowski, Tomasz Marciniak, Szymon Drgas, Julian Balcerek, and Adam Konieczka |
| PPBW ST1-2 | 96 | Polish Language Resources for Speech Technology: JURISDIC LVCSR corpora | Grazyna Demenko, Stefan Grocholewski, Katarzyna Klessa, Zbigniew Rau |
| PPBW ST1-3 | 128 | Intelligent Search Engine for Prosecutor Files (InWAS) | Andrzej Dziech, Tomasz Rusc, Remigiusz Baran |
| PPBW ST1-4 | 124 | A Machine Translation System Developed for the Needs of Public Safety Improvement – Intermediate Report | Krzysztof Jassem |
| PPBW ST1-5 | Link Analysis of Fuel Laundering Scams and Implations of Results for Scheme Understanding and Prosecutor Strategy | Czesław Jędrzejek, Maciej Falkowski, Maciej Smoleński | |
| PPBW ST1-6 | 127 | MPI – System for Web Information Monitoring | Aleksander Pohl |
| "Information Technologies in application to the Public Security Research" Technical Papers (session 2) | |||
| PPBW ST2-1 | 131 | POINT-112-SMS: The Beta Prototype (demo) | Zygmunt Vetulani, Jacek Marciniak, Tomasz Obrebski, Marek Kubis, Jedrzej Osinski, Justyna Walkowska, Piotr Kubacki, Krzysztof Witalewski |
| PPBW ST2-2 | Speech technology applications to public security systems | Mariusz Ziólko | |
| Day 2, Saturday, 7.11 | |||
| Word sense disambiguation | |||
| WSD-1 | 8 | Using Relational Description of Meaning for Word Sense Disambiguation | Ewa Thlon and Tomasz Pedzimaz |
| WSD-2 | 29 | Ambiguous Arabic Words Disambiguation: The results | Laroussi Merhbene, Anis Zouaghi, Mounir Zrigui |
| WSD-3 | The WSD Development Environment | Rafal Mlodzki and Adam Przepiórkowski | |
| WSD-4 | 47 | Unsupervised Word Sense Disambiguation with Lexical Chains and Graph-based Context Formalization | Radu ION, Dan STEFANESCU |
| WSD-5 | 110 | Detecting Word Senses of Technical Terms in Patent Documents using Hierarchical Semantic Features | Yoshimi Suzuki, Fumiyo Fukumoto |
| Verb Valency | |||
| VV-1 | 23 | Using Lexicon-Grammar tables for French verbs in a large-coverage parser | Elsa Tolone, Benoit Sagot |
| VV-2 | 25 | Similarity measure between frames for Polish semantic valence dictionary | Elzbieta Hajnicz |
| VV-3 | 78 | Classifying Polysemies using a Graph-based Clustering | Fumiyo Fukumoto, Kazuyuki Yamashita, and Yoshimi Suzuki |
| VV-4 | 108 | Linking Czech Verb Valency Lexicon VerbaLex with FrameNet | Jirí Materna |
| Information retrival / Information extraction 1 | |||
| IR/IE1-1 | 5 | Who are you, you who speak? Transducer cascades for information retrieval | Denis Maurel, Nathalie Friburger, Iris Eshkol |
| IR/IE1-2 | 27 | Enhancing Opinion Extraction by Automatically Annotated Lexical Resources | Andrea Esuli and Fabrizio Sebastiani |
| IR/IE1-3 | 41 | Text classification of articles on Kenyan elections | Senja Pollak |
| IR/IE1-4 | 53 | Technical Trend Analysis by Analyzing Research Papers' Titles | Kondo Tomoki, Hidetsugu Nanba, Toshiyuki Takezawa, Manabu Okumura |
| IR/IE1-5 | 35 | Temporal Expressions: Comparisons in a Multilingual Corpus | Emeline Lecuit, Denis Maurel, Dusko Vitasz, Cvetana Krstec |
| Text annotation 1 | |||
| TAN1-1 | 6 | BioExcom: Automatic Annotation and categorization of speculative sentences in biological literature by a Contextual Exploration processing | Julien Descles, Motasem Alrahabi, Jean-Pierre Descles |
| TAN1-2 | 30 | Which XML standards for multilevel corpus annotation? | Adam Przepiórkowski and Piotr Banski |
| TAN1-3 | 44 | A Prolog format for corpus markup | Tomas By |
| Corpora building | |||
| COR-1 | 40 | Compilation of Corpus Academicum Lithuanicum (CorALit): process, results, perspectives | Aurelija Usoniene, Linas Butenas, Birute Ryvityte, Jolanta Sinkuniene, Erika Jasionyte, Algimantas Juozapavicius |
| COR-2 | 99 | Speech Corpus designed for Context based European Portuguese TTS | Maria Barros, Bernd Mobius |
| COR-3 | 117 | Czech Senior COMPANION: Wizard of Oz Data Collection and Expressive Speech Corpus Recording | Martin Gruber, Milan Legat, Pavel Ircing, Jan Romportl, Josef Psutka |
| Machine Translation 1 | |||
| MT1-1 | 2 | Parsing Statistical Machine Translation Output | Simon Carter and Christof Monz |
| MT1-2 | 42 | Translation and Transliteration of Arabic Named Entities | Hela Fehri, Kais Haddar and Abdelmajid Ben Hamadou |
| MT1-3 | 58 | Packing it all up in search for a language independent MT quality measure tool | Kimmo Kettunen |
| Text annotation 2 | |||
| TAM2-1 | 74 | The Corpus Analysis Toolkit: Analysing Multilevel Annotations | Stephen Wilson and Julie Carson-Berndsen |
| TAN2-2 | 101 | Interlingual annotation of texts in the OMNIA project | David Rouquet, Hong-Thai Nguyen |
| TAN2-3 | 105 | The Language Archiving Technology domain | Alexander Koenig, Jacquelijn Ringersma, Paul Trilsbeek |
| Computational Semantics 1 | |||
| CS1-1 | 11 | Event-Time Temporal Relation Classification Using Syntactic Tree Kernels | Seyed Abolghasem Mirroshandel, Mahdy Khayyamian, Gholamreza Ghassem-Sani |
| CS1-2 | 13 | The experimental analysis of the natural language used for describing qualitative spatial relations between objects | Jedrzej Osinski |
| CS1-3 | 36 | Noun/Verb Inference | Paul Bedaride, Claire Gardent |
| Lexicons | |||
| LEX-1 | 19 | Evaluating an automatically extracted syntactic lexicon | Claire Gardent |
| LEX-2 | 50 | Usability improvements in the lexicographic framework Toposlaw | Marcin Wolinski, Agata Savary, Piotr Sikora, Malgorzata Marciniak |
| LEX-3 | 86 | Acquiring bilingual lexica from keyword listings | Filip Gralinski, Krzysztof Jassem, Roman Kurc |
| Speech 2 | |||
| SP2-1 | 79 | Finite State Based Speech Recognition Input Interface For Mobile GPS Systems | Yin-Wei Chung and Jui-Feng Yeh |
| SP2-2 | 81 | Complex SOM network as a Language Model for Large Vocabulary Continuous Speech Recognition | Leszek Gajecki, Ryszard Tadeusiewicz |
| SP2-3 | 32 | Objective Optimisation of Automatic Speech-to-Phoneme Alignment Systems | Ladan Baghai-Ravary, Greg Kochanski, and John Coleman |
| Computational Semantics 2 | |||
| CS2-1 | 68 | Dis-simulations, Human Language Technologies And Criminal Exploitation | Dwight Holbrook |
| CS2-2 | 77 | Effect of Overt Pronoun Resolution in Topic Tracking | Fumiyo Fukumoto, Yoshimi Suzuki |
| CS2-3 | 107 | Combining Specialized Entailment Engines | Bernardo Magnini and Elena Cabrio |
| CS2-4 | 121 | Semantic analysis elements in the Thetos-3 system | Julia Romaniuk, Nina Suszczanska, Przemyslaw Szmal |
| Summarization / Text Generation | |||
| STG-1 | 24 | Experimenting with Automatic Text Summarization for Arabic | Mahmoud El-Haj, Udo Kruschwitz, Chris Fox |
| STG-2 | 54 | Automatic Evaluation of Texts by Using Paraphrases | Kazuho Hirahara, Hidetsugu Nanba, Toshiyuki Takezawa, Manabu Okumura |
| STG-3 | 103 | Taittingen: A Biographical Text Generation System | Olivier Blanc, Noemi Boubel |
| STG-4 | 123 | Sentiment Intensity: Is It a Good Summary Indicator? | Mijail Kabadjov, Alexandra Balahur, Ester Boldrini |
| Day 3, Sunday, 8.11 | |||
| Speech 3 | |||
| SP3-1 | 83 | Using an underspecified ASR system as an indicator for phonetic similarity | Mark Kane, Julie Mauclair, Julie Carson-Berndsen |
| SP3-2 | 92 | Constructing a Multilingual Phoneme List for Polyglot Speech Synthesiser | Nur-Hana Samsudin, Mark Lee |
| SP3-3 | 100 | Semi-Supervised Transductive Speaker Identification | Oscar Tackstrom |
| Text analysis 1 | |||
| TA1-1 | 17 | A first study of the complete enumeration of all analogies contained in a text | Julien Gosme and Yves Lepage |
| TA1-2 | 21 | Automatic Author Attribution for Short Text Documents | Monika Nawrot |
| TA1-3 | 115 | Clues to Compare Languages for Morphosyntactic Analysis: A Study Run on Parallel Corpora and Morphosyntactic Lexicons | Helena Blancafort, Claude de Loupy |
| Terminology | |||
| TER-1 | 14 | Terminology Extraction from the Web | Manuela Sassi, Gabriella Pardelli, Sara Goggi |
| TER-2 | 18 | Unsupervised Extraction of Keywords from News Archives | Marco A. Palomino, Michael P. Oakes and Tom Wuytack |
| TER-3 | 116 | EXATOLP – An Automatic Tool for Term Extraction from Portuguese Language Corpora | Lucelene Lopes, Paulo Fernandes, Renata Vieira, Guilherme Fedrizzi |
| Ontologies / Wordnet | |||
| OWN-1 | 26 | Generalizing the EM-based semantic category annotation of NP/PP heads to wordnet synsets | Elzbieta Hajnicz |
| OWN-2 | 65 | An access layer to PolNet in POLINT-112-SMS | Marek Kubis |
| OWN-3 | 75 | A SUMO-based Semantic Analysis for Knowledge Extraction | Amal Zouaq, Michel Gagnon and Benoit Ozell |
| OWN-4 | 91 | Enriching Greek WordNet with Computer Science Domain Terms According to Baudet and Denhiere Text Comprehension Model | Panagiotis Blitsas, Maria Grigoriadou |
| OWN-5 | 119 | Ontologies for Metacognitive Monitoring and Repair of Dialogue | Aparna Subramanian and Tim Oates |
| Computational Morphology | |||
| CM-1 | 33 | Commonality across vocabulary structures as an estimate of the proximity between languages | Yves Lepage, Adrien Lardilleux and Julien Gosme |
| CM-2 | 38 | Automatic Affix Discovery | Tom Richens |
| CM-3 | 45 | Annotating Sanskrit corpus: adapting IL-POSTS | Girish Nath Jha, Madhav Gopal, Diwakar Mishra |
| CM-4 | 102 | The Inflectional Morphology of Bulgarian Definite Article in DATR | Velislava Stoykova |
| Information retrival / Information extraction 2 | |||
| IR/IE2-1 | 76 | Multilingual Opinion Holder and Target Extraction using Knowledge-Poor Techniques | Taras Zagibalov, John Carroll |
| IR/IE2-2 | 80 | A comparison of Information Extraction and Text Segmentation for Web Content Mining | Pavlina Fragkou |
| IR/IE2-3 | 87 | Using Wikipedia to Improve Precision of Contextual Advertising | Alexander Pak |
| IR/IE2-4 | 111 | Term ambiguity and variation in biomedical nomenclature and literature - problems for information extraction | Elzbieta Dura |
| Language Teaching | |||
| LT-1 | 31 | The Relevance of Variations in Auditory Perception for Second Language Teaching and Learning | Kiran Pala, Sachin Joshi, Prakash Mondal |
| LT-2 | 106 | A Software System for Learning the Vocabulary and Collocations: Results of a Training Experiment | Pavel Diachenko |
| LT-3 | 73 | Effective authoring procedure for e-learning courses’ development in Philological curriculum based on LOs ideology | G. Kedrova, A. Yegorov, M. Volkova |
| LT-4 | 56 | Software for Complex Examination on Natural Languages | Pavel Pankov, Polina Dolmatova |
| Text analysis 2 | |||
| TA2-1 | 37 | OTTO: A Tool for Diplomatic Transcription of Historical Texts | Stefanie Dipper and Martin Schnurrenberger |
| TA2-2 | 67 | Corpus Clouds - facilitating text analysis by means of visualizations | Chris Culy, Verena Lyding |
| TA2-3 | 94 | Extracting and Visualizing Quotations from News Wires | Eric de La Clergerie, Benoit Sagot, Rosa Stern, Pascal Denis, Gaelle Recource and Victor Mignot |
| TA2-4 | 43 | Using SRX standard for sentence segmentation in Language Tool | Marcin Milkowski, Jaroslaw Lipski |
| Machine Translation 2 | |||
| MT2-1 | 69 | A Solution for in Context and Collaborative Localization of most Commercial and Free Software | Amel Fraisse, Christian Boitet, Herve Blanchon, Valerie Bellynck |
| MT2-2 | 85 | Translation and Language Processing Laboratory: Modern Greek Language Resources, Tools, Applications – A Brief Review | Tita Kyriacopoulou, Olympia Tsaknaki, Eleni Tziafa |
| MT2-3 | 93 | The Impact of Morphological Errors in Phrase-based Statistical Machine Translation from English and German into Swedish | Oscar Tackstrom |
| MT2-4 | 95 | Cultural divergences, multilingual thesauri and the EHEA | Barbara De Santis |
|
|
|
As at the 2nd and 3rd Language and Technology Conferences (2005, 2007) special awards will be granted to the best student papers. Regular or PhD students (on the date of paper submission) are eligible. In 2005 the Jury, composed of the Program Committee members present at the conference, awarded this distinction to: Ronny Melz (University of Leipzig), Hartwig Holzapfel (University of Karlsruhe), Marcin Woliński (IPI PAN, Warsaw). In 2007 this distinction went to Daria Fišer (University of Ljubljana) |
|
|
|
Participants from some non-EU countries may need visas to enter Poland. Visa delivery is exclusively in competence of the appropriate Visa Authorities (of Poland or other Schengen countries). If you have any doubts, we recommend you to check your situation with the nearest Polish Consulate in your country of residence. If necessary, we can confirm that we have accepted your paper for presentation at the conference and that you are expected to present your paper personally. Upon request, we may also write a confirmation letter (in Polish) directly to the Polish Consulate indicated by you. To do this we will need a request letter (e-mail) from you in which you will provide us with the address of the Consulate you wish us to contact. To get information about countries whose citizens are not required to have a visa when entering Poland and to find important telephone numbers you may also visit the web site of the Polish Ministry of Foreign Affairs http://www.msz.gov.pl/index.php?document=2 (see Consular Information http://www.msz.gov.pl/Consular,Information,2345.html). |
|
|
|
This site is in progress. Further important practical information will be published shortly. Please consult this site again from time to time. |
|
|
|
There are several large scale events in Poznań at the LTC 2009 time (November 6-8, 2009). Therefore, we strongly recommend you to make the hotel reservation in advance. There are several standard possibilities to book via Internet. Also, a special offer for Conference participants has been prepared by the travel agency Zimny http://www.zimny.pl (mailto:zimny@zimny.pl). |
|
|
| Address: | The 4-th Language & Technology
Conference (LTC 2009) Adam Mickiewicz University Faculty of Mathematics and Computer Science Department of Computer Linguistics and Artificial Intelligence ul. Umultowska 87 PL 61-614 Poznań |
| E-mail: | ltc@amu.edu.pl |
| WWW: | www.ltc.amu.edu.pl |
|
|

|
|
|
 |
|
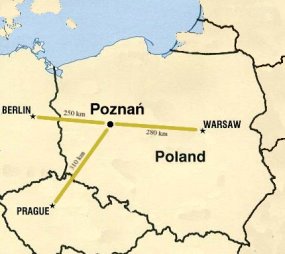 |
|
|
|
Even though we did our best to make sure all conference locations are within walking distance, conference guests may wish to use the public transport. Fortunately, Poznań boasts a vast public transport network. The timetable (by tram or bus line) can be viewed at http://www.mpk.poznan.pl/rozklad-jazdy. (After choosing the line, one has to choose the proper bus or tram stop in the right direction.) An interactive transportation map is available at http://www.info.poznan.pl/Map/MapControl.html?Id=0. (You type the street name in the text box to see the chosen part of town and display bus and tram lines by selecting A for buses and T for trams from the left upper corner menu.) A 10-minute adult ticket costs PLN 2.00, A 30-minute ticket costs PLN 3.60 and a 60-minute ticket is PLN 5.80. They are valid in both trams and buses. You have to validate the ticket in a special machine inside the vehicle. Within the time frame you can change lines. Normal tickets are valid also for the night buses and trams. You can buy tickets in one of the newspaper stands near bus stops. |
|
|
|
Electronic tickets Electronic tickets allowing conference participants to enter the Poznań International Fair area will be available in the Entrance Hall (Hol Wschodni). The tickets are valid for the three days of the conference. Conference participants should carry the tickets with them at all times. It is not possible to enter the Fair area without the ticket. Wi-Fi Free wireless Internet is available in pavilion 14B (where the conference takes place). Please choose the MPT network (unprotected). Taxi You can call a taxi free from the reception desk. Restaurants The following restaurants are in near proximity of pavilion 14B (where the conference takes place):
Tram trip On November 7 (Saturday) at 16:55 we meet by the reception desk to go on a guided tram tour around Poznań. Two historical trams will take conference participants from Dworzec Zachodni (Western Train Station) to Wrocławska Street. From there we will take a short walk to the City Hall, where we will meet the President of Poznań. The trams will leave from the stop by Dworzec Zachodni at 17:20. Because we will use the public tram network, it is impossible to leave with any delay! |
|
|
|
The currency of Poland is Polish złoty (PLN). Złoty is subdivided into 100 groszy (singular: grosz). As for September 26, 2007, the euro/złoty exchange rate is 4,29, the dollar/złoty exchange rate is 2,91. If you are arriving by plane, you can get to the city centre by bus or by taxi. Four bus lines run from the Poznań-Ławica Airport to the city centre: 48, 59, L (express line) and 242 (night bus line) (see information on public transport). Bus 59 departs from the airport grounds and bus 48 departs from Wyszeborska street (200m straight from terminal building). The bus needs approximately 20 minutes to reach the city centre. Poznań International Fair building complex is located near the "Bałtyk" stop. The taxi rank is located in front of the airport's arrival hall. You may also call a taxi (in Polish or English) by dialing the number 19622 (no prefixes). Depending on the traffic, you will pay PLN 25-40 to get to the city centre. |
 |