Submissions from:







































Submissions from:
|
|
|
|
as a Challenge for Computer Science and Linguistics |
|
|
|
|
|
|
|
|
|
|
 |
|
|
|
|
       
 |
 |
 |
|
Collegium Minus, Presidence |
and Computer Science |
|
|
|
|
Available movies |
TVP Poznan - Teleskop 26.11.2011 Day Two - 26.11.2011 - Work (by Maciej Bronikowski "Matejza") Day Two - 26.11.2011 - Leisure (by Maciej Bronikowski "Matejza") |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
|
|
|
Dear Colleagues, The 5th Language and Technology Conference (LTC'11), a meeting organized by the Faculty of Mathematics and Computer Science of Adam Mickiewicz University, Poznan, Poland in cooperation with the Adam Mickiewicz University Foundation, will take place on November 25-27, 2011. Since very beginning the meetings of the LTC series continue to address Human Language Technologies (HLT) as a challenge for computer science, linguistics and related fields. Fostering language technologies and resources remains an important mission in the dynamically changing information-saturated world. We aim at contributing to this mission and we invite you to join us in that at LTC'11 in November 2011, traditionally held in Poznań, Poland.
Zygmunt Vetulani |
|
|
|
The conference topics include the following (the ordering is not significative):
This list is by no means closed and we are open to further proposals. Please do not hesitate to contact us in order to feed us with your suggestions and ideas of how to satisfy your expectations concerning the program. The Program Committee is also open to suggestions concerning accompanying events (workshops, exhibits, panels, etc). Suggestions, ideas and observations may be addressed directly to the LTC Chair by email (vetulani@amu.edu.pl). |
|
|
| Zygmunt Vetulani (Adam Mickiewicz University, Poznań, Poland) - chair |
| Victoria Arranz (ELRA, France) |
| Nuria Bel (Univ. Pompeu Fabra, Spain) |
| Janusz S. Bień (Warsaw University, Poland) |
| Krzysztof Bogacki (Warsaw University, Poland) |
| Christian Boitet (IMAG, France) |
| Leonard Bolc (IPI PAN, Poland) |
| Lynne Bowker (University of Ottawa, Canada) |
| Gerhard Budin (Univ. Vienna, Austria) |
| Nicoletta Calzolari (ILC/CNR, Italy) |
| Nick Campbell (Trinity College Dublin, Ireland) |
| Julie Carson-Berndsen (University College Dublin, Ireland) |
| Khalid Choukri (ELRA, France) |
| Adam Dąbrowski (Poznań University of Technology, Poland) |
| Elżbieta Dura (University of Skovde, Sweden) |
| Katarzyna Dziubalska-Kołaczyk (Adam Mickiewicz University, Poznań, Poland) |
| Tomaz Erjavec (Josef Stefan Institute, Slovenia) |
| Cedrick Fairon (University of Louvain, Belgium) |
| Christiane Fellbaum (Princeton University, USA) |
| Maria Gavrilidou (ILSP, Greece) |
| Dafydd Gibbon (University of Bielefeld, Germany) |
| Marko Grobelnik (J. Stefan Institute, Slovenia) |
| Franz Guenthner (Ludwig-Maximilians-University München, Germany) |
| Jan Hajic (Charles Univ., Czech Republic) |
| Eva Hajičová (Charles University, Czech Republic) |
| Roland Hausser (Erlangen, Germany) |
| Steven Krauwer (University of Utrecht, Netherlands) |
| Eric Laporte (University Marne-la-Vallee, France) |
| Yves Lepage (University Caen Basse-Normandie, France) |
| Gerard Ligozat (LIMSI/CNRS, France) |
| Natalia Loukachevitch (Research Computing Center of Moscow State University, Russia) |
| Bente Maegaard (Centre for Language Technology, Denmark) |
| Bernardo Magnini (ITC IRST, Italy) |
| Alfred Majewicz (UAM, Poland) |
| Joseph Mariani (LIMSI-CNRS, France) |
| Jacek Martinek (Poznań University of Technology, Poland) |
| Gayrat Matlatipov (Urgench State University,Uzbekistan) |
| Keith J. Miller (MITRE, USA) |
| Asunción Moreno (UPC, Spain) |
| Jan Odijk (Univ. Utrecht, The Netherlands) |
| Nicholas Ostler (Linguacubun Ltd., UK) |
| Karel Pala (Masaryk University, Czech Republic) |
| Pavel S. Pankov (National Academy of Sciences, Kyrgyzstan) |
| Patrick Paroubek (LIMSI-CNRS, France) |
| Stelios Piperidis (ILSP, Greece) |
| Emil Pływaczewski (University of Bialystok, Poland) |
| Gabor Proszeky (Morphologic, Hungary) |
| Adam Przepiórkowski (IPI PAN, Poland) |
| Reinhard Rapp (University Mainz, Germany) |
| Mohsen Rashwan (Cairo Univ., Egypt) |
| Mike Rosner (University of Malta) |
| Justus Roux (University of Stellenbosch, South Africa) |
| Vasile Rus (University of Memphis, Fedex Inst. of Technology, USA) |
| Rafał Rzepka (University of Hokkaido, Japan) |
| Kepa Sarasola Gabiola (Univ. del Pas Vasco, Spain) |
| Frédérique Ségond (Xerox, France) |
| Zhongzhi Shi (Institute of Computing Technology / Chinese Academy of Sciences, China) |
| Hanna Szafrańska (UAM Foundation, Poland) |
| Ryszard Tadeusiewicz (AGH, Poland) |
| Marko Tadić (Croatian Academy of Sciences and Arts, Croatia) |
| Dan Tufiş (RCAI, Romania) |
| Hans Uszkoreit (DFKI, Germany) |
| Tamás Váradi (RIL, Hungary) |
| Cristina Vertan (Univ. Hamburg, Germany) |
| Piek Vossen (University of Amsterdam, Netherlands) |
| Tom Wachtel (Perlocutio, UK) |
| Jan Węglarz (Poznań University of Technology, Poland) |
| Mariusz Ziółko (AGH, Poland) |
| Richard Zuber (CNRS, France) |
|
|
| Zygmunt Vetulani - Chair |
| Wojciech Czarnecki |
| Marek Kubis - secretary |
| Jacek Marciniak |
| Tomasz Obrębski |
| Jędrzej Osiński |
| Grzegorz Taberski |
| All of Adam Mickiewicz University, Poznań, Poland |
| Contact: ltc@amu.edu.pl |
|
|
|
The conference language is English. |
|
|
|
The conference accepts papers in English. Papers (5 formatted pages in the conference format) are due by July 31, 2011 (midnight, any time zone) and should not identify the author(s) in any manner. In order to facilitate submission we have decided to reduce the formatting requirements as much as possible at this stage. Please, however, do observe the following:
The Word template (ELRA/LREC based format) is available here. Detailed guidelines for the final submission of accepted papers will be published on the conference web site before October 15, 2011. All submissions are to be made electronically via the LTC'11 web submission system (EasyChair). Acceptance/rejection notification will be sent by September 27, 2011. |
|
|
|
Final papers are due by October 27, 2011. Please use templates for MS Word. In any case, please do observe the following:
Final papers should be sent by e-mail to ltc@amu.edu.pl as an attachment. A security copy should be sent to jacekmar@amu.edu.pl.
The PAPERID is your paper ID from EasyChair. |
|
|
|
Acceptance will be based on the reviewers' assessments (anonymous
submission model). The accepted papers will be published in the conference
proceedings (hard copy, with ISBN number) and on CD-ROM. The abstracts
of the accepted contributions will also be made available via the
conference page (during its lifetime). Publication requires full
electronic registration and payment of the conference fee (full
registration) by at least one of the co-authors before October 27, 2011.
|
|
As this was the case for post-LTC'07 (v. 5603) and LTC'09 (v. 6562), a post-proceedings volume with the selection of 40 revised and extended versions of LTC'11 papers will be published.
It has been accepted (2013) for publication in the Springer series Lecture Notes in Artificial Intelligence.
The LTC 2005 post conference selection appeared in form of Special Issue of Archives of Control Sciences (2005, Volume 15 nb. 3 and Volume 15 nb. 4) |


|
|
The LTC 2007 post-conference volume (revised, extended papers) appeared in the Springer Verlag series LNAI (vol. 5603). |
 |
|
The LTC 2009 post-conference volume (revised, extended papers) has just appeared (April, 2011) in the Springer Verlag series LNAI (vol. 6562). |
 |
|
|
*) This extension was possible due to the special arrangement with the Publisher of the proceedings. **) We are sorry to inform you about a delay of the acceptance/refusal paper notification. We are still expecting some missing reviews. We will do our best to reduce this delay to the minimum. |
|
|
|
Registration deadline for the Authors is November 6.
|
|
|
| Day 1, Friday, November 25, 2011 | |
| Collegium Iuridicum Novum - Auditorium | |
|
8:00 - 9:30 |
Registration and coffee |
|
9.30 - 9:50 |
Introduction |
|
Welcome address by Rector of the Adam Mickiewicz University (Bronisław Marciniak) |
|
|
Welcome address by Major of Poznań (Ryszard Grobelny) |
|
|
Address by the President of the Council of National Center for Research and Development (Jerzy Kątcki, Warsaw, Poland) |
|
|
9:50 - 10:30 |
Invited presentation by Kimmo Rossi (EU) "Connecting Europe - New Opportunities for Language Technologies in the Horizon" |
|
10:30 - 11:10 |
Invited Talk on the "FlaReNet recommendations and future prospects" by Nicoletta Calzolari (Pisa, Italy) |
|
11:15 - 12:30 |
Panel on Strategic Priorities for LT in Europe (moderated by Hans Uszkoreit, Saarbruecken, Germany) |
|
12:30 - 13:50 |
Lunch Break |
| Hotel Polonez - Conference Area | |
|
Less-Resourced Languages 2011 Special Track |
|
|
13:50 - 13:55 |
Introduction |
|
13:55 - 15:05 |
European approach for addressing the gaps |
|
15:05 - 16:35 |
Monolingual Processing of LRL |
|
16:35 - 17:00 |
Coffee break |
|
17:00 - 17:30 |
Bilingual Processing of LRL |
|
17:30 - 19:00 |
Multilingual Processing for LRL |
|
19:00 - 19:20 |
General discussion on Strategies for Addressing the LRL Gaps |
|
20:00 - 22:30 |
Welcome Reception (Bus departure at 19:45) |
| Day 2, Saturday, November 26, 2011 | |||
| Hotel Polonez - Conference Area | |||
|
8:30 - 9:50 |
Ontologies / wordnet 1 |
Text analysis 1 |
Text classification |
|
9:50 - 10:20 |
Coffee Break |
||
|
10:20 - 11:40 |
Computational semantics 1 |
Text analysis 2 |
Speech 1 |
|
11:40 - 11:50 |
Technical Break |
||
|
11:50 - 12:50 |
Verb valency / WSD |
Text analysis 3 |
Language resources and tools 1 |
|
12:50 - 14:00 |
Lunch Break |
||
|
14:00 - 15:00 |
Dialogue 1 |
Machine translation 1 |
Language resources and tools 2 |
|
15:00 - 15:10 |
Technical Break |
||
|
15:10 - 16:30 |
Dialogue 2 |
Text analysis 4 |
Speech 2 |
|
16:30 - 17:00 |
Demo session |
Coffee Break |
|
|
17:00 - 18:20 |
Applications |
Parsing 1 |
|
|
18:20 - 18:40 |
|||
|
20:00 - 00:00 |
Conference Gala Dinner / Best Student Paper Award |
||
| Day 3, Sunday, November 27, 2011 | |||
| Hotel Polonez - Conference Area | |||
|
8:30 - 9:30 |
Computational semantics 2 |
Machine translation 2 |
Speech 3 |
|
9:30 - 10:00 |
Coffee Break |
||
|
10:00 - 11:20 |
IE /IR |
Machine translation 3 |
Language resources and tools 3 |
|
11:20 - 11:30 |
Technical Break |
||
|
11:30 - 12:50 |
Ontologies / wordnet 2 |
Parsing 2 |
Text annotation |
|
12:50 - 14:00 |
Lunch Break |
||
| Collegium Iuridicum Novum - Auditorium | |||
|
14:00 - 14:45 |
Gerard Ligozat: Invited Talk on the "Extracting, Representing, and Reasoning about Time and Space in Texts and Discourse" |
||
|
14:45 - 15:15 |
Coffee Break |
||
|
15:15 - 15:45 |
Closure |
||
|
|
| Day 1: November 25, 2011 | |
| Session: European approach for addressing the gaps | |
| 14:25 - 14:35 | |
| Detecting Gaps in Language Resources and Tools in the Project CESAR | Radovan Garabík, Svetla Koeva, Maciej Ogrodniczuk, Marko Tadić, Tamás Váradi and Duško Vitas |
| Session: Monolingual Processing of LRL | |
| 15:05 - 16:35 | |
| Strategies to develop Language Technologies for Less-Resourced Languages based on the case of Basque | Ińaki Alegria, Xabier Artola, Arantza Diaz de Ilarraza and Kepa Sarasola |
| A first LVCSR system for Luxembourgish, an under-resourced European language | Martine Adda-Decker, Lori Lamel and Gilles Adda |
| Spell Checking an Agglutinative Language: Quechua | Annette Rios |
| Challenges for Design of Pronunciation Lexicon Specification (PLS) for Punjabi Language | Swaran Lata |
| Challenges in Developing LRs for Non-Scheduled Languages: A Case of Magahi | Ritesh Kumar, Bornini Lahiri and Deepak Alok |
| Challenges and Open Problems in Persian Text processing | Mehrnoush Shamsfard |
| Session: Bilingual Processing of LRL | |
| 17:00 - 17:30 | |
| A Survey on Existing Chinese-Japanese Bilingual Resources | Jing Sun and Yves Lepage |
| Quizzes on Tap: Exporting a Test Generation System from one Less-Resourced Language to Another | Montse Maritxalar, Elaine Ui Donnchadha, Jennifer Foster and Monica Ward |
| Session: Multilingual Processing for LRL | |
| 17:30 - 19:00 | |
| A Multilingual Text Normalization Approach | Brigitte Bigi |
| Creating Multilingual Parallel Corpora in Indian Languages | Narayan Choudhary and Girish Jha |
| Issues in annotating less resourced languages – the case of Hindi from Indian Languages Corpora Initiative (ILCI) | Pinkey Nainwani, Esha Banerjee, Shiv Kaushik and Girish Nath Jha |
| Natural Language Ontology of Action. A gap with huge consequences for Natural Language Understanding and Machine Translation | Massimo Moneglia |
| Principles of Part-of-Speech (POS) Tagging of Indian Language Corpora | Niladri Sekhar Dash |
| Inducing grammar from IGT | Lars Hellan and Dorothee Beerman |
| Day 2: November 26, 2011 | |
| Session OWN1: Ontologies/Wordnet 1 | |
| 8:30 - 9:50 | |
| Acquiring Relational Patterns from Wikipedia: A Case Study | Rahmad Mahendra, Lilian Wanzare, Bernardo Magnini, Raffaella Bernardi and Alberto Lavelli |
| Enhancing tagging systems by wordnet based ontologies | Jacek Marciniak |
| Semi-automated construction of a topic ontology from research papers in the domain of language technologies | Jasmina Smailović and Senja Pollak |
| Semi-Automatic Extension of GermaNet with Sense Definitions from Wiktionary | Verena Henrich, Erhard Hinrichs and Tatiana Vodolazova |
| Session TANA1: Text Analysis 1 | |
| 8:30 - 9:50 | |
| Digging for Names in the Mountains: Combined Person Name Recognition and Reference Resolution for German Alpine Texts | Sarah Ebling, Rico Sennrich, David Klaper and Martin Volk |
| Recognizing Named Entities using Automatically Extracted Transduction Rules | Damien Nouvel, Jean-Yves Antoine, Nathalie Friburger and Arnaud Soulet |
| Temporal Expression Recognition Using Dependency Trees | Paweł Mazur and Robert Dale |
| Temporal Relation Classification Using Dependency Convolution Tree Kernels | Seyed Abolghasem Mirroshandel and Gholamreza Ghassem-Sani |
| Session TCLA: Text Classification | |
| 8:30 - 9:50 | |
| Patent Document Classification using expanded Technical Term Thesaurus | Yoshimi Suzuki |
| Relation based text classifier | Ewa Thlon and Tomasz Pędzimąż |
| The Use of Latent Semantic Indexing to Cluster documents into their subject areas | Roseline Antai, Chris Fox and Udo Kruchwitz |
| Session SEM1: Computational Semantics 1 | |
| 10:20 - 11:40 | |
| End-to-end coreference resolution baseline system for Polish | Maciej Ogrodniczuk and Mateusz Kopeć |
| Resolving Anaphors in Sanskrit | Madhav Gopal and Girish Nath Jha |
| Thel, a language for formalization of Polish Sign Language utterances | Nina Suszczańska and Przemysław Szmal |
| Unsupervised Coreference Resolution Using a Multi-pass Graph Labeling Approach | Nafise Sadat Moosavi and Gholamreza Ghassem-Sani |
| Session TANA2: Text Analysis 2 | |
| 10:20 - 11:40 | |
| Automatic extraction of multiword lexical units from Polish text | Michał Woźniak |
| Automatic Selection of Clustering Algorithms for Word Sense Disambiguation | Bartosz Broda and Wojciech Mazur |
| Identifying Event and Subject of Continuous News Streams for Multi-Document Summarization | Yoshimi Suzuki and Fumiyo Fukumoto |
| Identifying Lexical Bundles in Secondary School Textbooks | Carola Ribeck |
| Session SP1: Speech 1 | |
| 10:20 - 11:40 | |
| Comparison of Syllable and Triphone Based Speech Recognition for Amharic | Martha Yifiru Tachbelie, Laurent Besacier and Solange Rossato |
| Impact of choice of training data and patterns reduction in speaker dependent speech recognition | Jakub Gałka, Tomasz Jadczyk, Bartosz Ziółko and Dawid Skurzok |
| Language modeling using SOM network | Leszek Gajecki and Ryszard Tadeusiewicz |
| Speech Recognition Training for Pre-Elementary School Language Learning | Alejandro Curado-Fuentes, J. Enrique Agudo-Garzón and Héctor Sánchez-Santamaría |
| Session VAL: Verb Valency/WSD | |
| 11:50 - 12:50 | |
| A Syntactic Valency Lexicon for Persian Verbs: The First Steps towards Persian Dependency Treebank | Mohammad Sadegh Rasooli, Amirsaeid Moloodi, Manouchehr Kouhestani and Behrouz Minaei-Bidgoli |
| Ordering Slots of Semantically Related Schemata of Polish Verbs | Elżbieta Hajnicz |
| Polish Word Sketches | Adam Radziszewski, Adam Kilgarriff and Robert Lew |
| Session TANA3: Text Analysis 3 | |
| 11:50 - 12:50 | |
| Enhancing the discovery of informality levels in Web 2.0 texts | Alejandro Mosquera and Paloma Moreda |
| Incremental Genre Detection for Recommendation in the Long Tail | Paula Cristina Vaz and David Martins De Matos |
| SurZe: A Tool for Pragmatic NLP | Ritesh Kumar |
| Session LRT1: Language Resources and Tools 1 | |
| 11:50 - 12:50 | |
| Through Wordnet to Lexicon Grammar | Zygmunt Vetulani, Grażyna Vetulani |
| National Corpus of Polish | Adam Przepiórkowski, Mirosław Bańko, Rafał L. Górski, Barbara Lewandowska-Tomaszczyk, Marek Łaziński and Piotr Pęzik |
| Extending a Tool Resource Framework with U-Compare | Mike Rosner, Andrew Attard, Paul Thompson, Albert Gatt and Sophia Ananiadou |
| Session DIA1: Dialogue 1 | |
| 14:00 - 15:00 | |
| A comparative study of intention-level user simulations on the Communicator data | Magdalena Wolska, Ruth Schreiber and Dietrich Klakow |
| Towards the Modelling of Backend Functionalities in Task-Oriented Dialogue Systems | Markus Berg |
| Unsupervised learning of dialogue structure in task-oriented dialogues | Tassilo Barth, Dietrich Klakow and Magdalena Wolska |
| Session MT1: Machine Translation 1 | |
| 14:00 - 15:00 | |
| A Study of The Number of Proportional Analogies between Marker-based Chunks in 11 European Languages | Kota Takeya and Yves Lepage |
| Exploring N-grams Distribution for Sampling-based Alignment | Juan Luo, Adrien Lardilleux and Yves Lepage |
| Two Memory-Based Methods for Phrase Alignment | Johan Segura and Violaine Prince |
| Session LRT2: Language Resources and Tools 2 | |
| 14:00 - 15:00 | |
| A Preliminary Version of Składnica – a Treebank of Polish | Marcin Woliński, Katarzyna Głowińska and Marek Świdziński |
| Crowdsourcing for Language Resource Development: Critical Analysis of Amazon Mechanical Turk Overpowering Use | Gilles Adda, Benoît Sagot, Karën Fort and Joseph Mariani |
| Defining the Annotation Scheme of a Treebank: The End-Use Perspective | Kristiina Muhonen and Tanja Purtonen |
| Session DIA2: Dialogue 2 | |
| 15:10 - 16:30 | |
| Active Learning to Speed-up the Training Process for Dialogue Act Labelling | Fabrizio Ghigi, Carlos David Martinez-Hinarejos and José Miguel Benedi |
| Extraction of query conditions from queries formulated in natural Polish language | Piotr Wnęk and Jan Jagielski |
| Modelling semantic alignment in emergency dialogue | Jolanta Bachan |
| How-To Question-Answering: hints extraction | Marc Canitrot, Sarah Bourse, Thomas De Filipo, Pierre Yves Roger and Patrick Saint Dizier |
| Session TANA4: Text Analysis 4 | |
| 15:10 - 16:30 | |
| A Rule based Method for the Identification of TAM features in a PoS Tagged Corpus | Narayan Choudhary, Pramod Pandey and Girish Nath Jha |
| Applying Rule-Based Normalization to Different Types of Historical Texts – An Evaluation | Marcel Bollmann, Florian Petran and Stefanie Dipper |
| Enhancing Labeled Data using Unlabeled Data for Topic Tracking | Fumiyo Fukumoto and Yoshimi Suzuki |
| Text normalization using deep and surface parsing | Krzysztof Jassem and Marta Wieczorek |
| Session SP2: Speech 2 | |
| 15:10 - 16:30 | |
| Adaptable Phone and Syllable HMM-Based Ibibio TTS Systems | Moses Ekpenyong, Eno-Abasi Urua, Escor Udosen and EmemObong Udoh |
| Kernel matrix size reduction methods for speaker verification | Szymon Drgas and Adam Dąbrowski |
| Slovak Automatic Transcription and Dictation System for the Judicial Domain | Milan Rusko, Jozef Juhár, Marian Trnka, Ján Staš, Sakhia Darjaa, Daniel Hládek, Miloš Cerňak, Marek Papco, Róbert Sabo, Matúš Pleva, Marian Ritomský and Martin Lojka |
| The intonation of backchannels in Italian task-oriented dialogues: cues to turn-taking dynamics, information status and speaker’s attitude | Michelina Savino |
| Session: Demo | |
| 16:30 - 18:40 | |
| Language Processing Chains in ATLAS | Anelia Belogay, Dan Cristea, Eugen Ignat, Diman Karagiozov, Svetla Koeva, Maciej Ogrodniczuk, Adam Przepiórkowski, Polivios Raxis and Cristina Vertan |
| The TextCoop System: processing explanations in procedures | Sarah Bourse, Patrick Saint-Dizier and Marc Canitrot |
| The KOMODO question-answering system: providing hints in do-it-yourself and gardening activities | Marc Canitrot, Sarah Bourse, Pierre-Yves Roger and Patrick Saint-Dizier |
| Demonstration of DTAG and Translog-II:Linking Dependency Treebank Representations with Text-production Behaviour | Michael Carl and Henrik Høeg Müller |
| The Production of Many Voices for Tone Language Systems | Moses Ekpenyong, Eno-Abasi Urua, Escor Udosen and EmemObong Udoh |
| PLLM – Language modeling using SOM network | Leszek Gajecki and Ryszard Tadeusiewicz |
| WUpdate – a tool for transforming WordNet-like lexical databases | Marek Kubis |
| CESAR resources in META-SHARE repository | Radovan Garabík, Svetla Koeva, Cvetana Krstev, Maciej Ogrodniczuk, Adam Przepiórkowski, Mladen Stanojević, Marko Tadić, Tamás Váradi, Klára Vicsi“Duško Vitas and Sanja Vraneš |
| System for Transcribing and Accessing Historical Archive of Czech Radio | Jan Nouza, Karel Blavka, Marek Bohac, Michaela Kucharova, Jindrich Zdansky and Ladislav Seps |
| UAM Text Tools | Tomasz Obrębski |
| Polsyn, Polsem, and Polin – the deep parser, semantic analyzer, and linearizer of the Thetos translator | Nina Suszczańska and Przemysław Szmal |
| The Thetos system, Polish text into sign language translator | Nina Suszczańska and Przemysław Szmal |
| POLINT-112-SMS | Zygmunt Vetulani and Jacek Marciniak |
| PolNet – Polish Wordnet | Zygmunt Vetulani, Wojciech Czarnecki, Marek Kubis, Jacek Marciniak, Tomasz Obrębski, Jędrzej Osiński and Grzegorz Taberski |
| Session APP: Applications | |
| 17:00 - 18:20 | |
| A Humanoid Robot as a Translator from Text to Sign Language | Siham Al-Rikabi and Verena Hafner |
| Discussing the impact of a new Assistive Reading tool on Greek Dyslexic children | Theologos Athanaselis, Stelios Bakamidis, Ioannis Dologlou, Evmorfia N. Argyriou and Antonis Symvonis |
| Energetic Definition of a Language and Software for 3D-presentations of Notions of Natural Languages | Pavel Pankov and Erkin Kasymov |
| Session PAR1: Parsing 1 | |
| 17:00 - 18:40 | |
| A Hybrid Approach to Kashmiri Shallow Parsing | Riyaz Ahmad Bhat and Dipti Mishra Sharma |
| Lexical Disambiguation in LTAG using Left Context | Claire Gardent, Yannick Parmentier, Guy Perrier and Sylvain Schmitz |
| Parsing Coordination Extragrammatically | Valmi Dufour-Lussier, Bruno Guillaume and Guy Perrier |
| Problems of conjunction based analysis of complicated compound sentences in the Polish language | Katarzyna Bartela |
| Obtaining PCFG Probabilities Based on the Corpus | Paweł Skórzewski |
| Day 3: November 27, 2011 | |
| Session SEM2: Computational Semantics 2 | |
| 8:30 - 9:30 | |
| Normalization of Term Weighting Scheme for Sentiment Analysis | Alexander Pak and Patrick Paroubek |
| Spatial reasoning and disambiguation in the process of knowledge acquisition | Marcin Walas and Krzysztof Jassem |
| The spatio-temporal relation of the XCDC model conceptualized in a natural language | Jędrzej Osiński |
| Session MT2: Machine Translation 2 | |
| 8:30 - 9:30 | |
| A Hybrid Multi-Word Terms Alignment Approach Using Word Co-occurrence with a Bilingual Lexicon | Morgane Marchand and Nasredine Semmar |
| Comparing CBMT Approaches for German-Romanian | Monica Gavrila and Natalia Elita |
| Training Statistical Machine Translation with Multivariate Mutual Information | Cyrine Nasri, Kamel Smaili and Chiraz Latiri |
| Session SP3: Speech 3 | |
| 8:30 - 9:30 | |
| Affective Interaction with a Companion Robot for Hospitalized Children: a Linguistically based Model for Emotion Detection | Marc Le Tallec, Jean-Yves Antoine, Jeanne Villaneau and Dominique Duhaut |
| Impact of Pronunciation Variant Frequency on Automatic Non-Native Speech Segmentation | Denis Jouvet, Larbi Mesbahi, Anne Bonneau, Dominique Fohr, Irina Illina and Yves Laprie |
| Speech Segmentation for Collecting Non-Uniform Speech Units | Tiberiu Boroş |
| Session IER: IE/IR | |
| 10:00 - 11:20 | |
| Automatic Generation Approach of Short Titles | Cédric Lopez, Violaine Prince and Mathieu Roche |
| Information Extraction for Czech Based on Syntactic Analysis | Vít Baisa and Vojtěch Kovář |
| Information extraction support system applied in data search in the domain of biomedical engineering | Andrzej Opaliński, Wojciech Turek, Mirosław Głowacki and Anna Romanowska-Pawliczek |
| Stemming Finnish for Information Retrieval – Comparison of an Old and a New Rule-based Stemmer | Kimmo Kettunen and Feza Baskaya |
| Session MT3: Machine Translation 3 | |
| 10:00 - 11:20 | |
| Estimating frequencies of inflected forms using simple frequency lists | Filip Graliński |
| CRITT NLP Resources for Translation Representation of User Activity Data in Translog-II | Michael Carl and Henrik Høeg Müeller |
| Text Genre - an Unexplored Parameter in Statistical Machine Translation | Monica Gavrila and Cristina Vertan |
| Using Cross-Language Information Retrieval for Machine Translation | Nasredine Semmar, Christophe Servan, Dhouha Bouamor and Ali Jaoua |
| Session LRT3: Language Resources and Tools 3 | |
| 10:00 - 11:20 | |
| Toward Integrated Lexico-Semantic Language Technology for Polish | Maciej Piasecki |
| Construction of an electronic dictionary on the base of a paper source | Agnieszka Mykowiecka, Katarzyna Głowińska, Piotr Rychlik and Jakub Waszczuk |
| Parallel and spoken corpora in an open repository of Polish language resources | Piotr Pęzik, Maciej Ogrodniczuk and Adam Przepiórkowski |
| A Bilingual Study of Knowledge-Rich Context Extraction in Russian and German | Anne-Kathrin Schumann |
| Session OWN2: Ontologies/Wordnet 2 | |
| 11:30 - 12:50 | |
| A tool for transforming WordNet-like databases | Marek Kubis |
| Extending wordnets by learning from multiple resources | Benoît Sagot and Darja Fišer |
| KABA Subject Heading Language as the Main Resource Subject Organization Tool in a Semantic Knowledge Base | Cezary Mazurek, Krzysztof Sielski, Justyna Walkowska and Marcin Werla |
| Session PAR2: Parsing 2 | |
| 11:30 - 12:50 | |
| Automatic Syntactic Analysis for Polish Language | Marcin Adamski and Michał Zimniewicz |
| Chunking of Polish: guidelines, discussion and experiments with Machine Learning | Marek Maziarz, Adam Radziszewski and Jan Wieczorek |
| Evaluation of Combining Data-Driven Dependency Parsers for Arabic | Maytham Alabbas and Allan Ramsay |
| Programming in DISLOG: some foundational elements | Patrick Saint Dizier |
| Session TANO: Text Annotation | |
| 11:30 - 12:50 | |
| A Memory-Based Tagger for Polish | Adam Radziszewski and Tomasz Śniatowski |
| Application of Video Processing Methods for Linguistic Research | Przemysław Lenkiewicz, Peter Wittenburg, Oliver Schreer and Stefano Masneri |
| Confidence measures in dialogue annotation by N-gram transducers | Carlos David Martinez Hinarejos, Vicent Tamarit and Jose Miguel Benedi |
| Orwell’s 1984 – the Case of Serbian Revisited | Cvetana Krstev, Duško Vitas and Aleksandra Trtovac |
|
|
|
Non-student participants:
To be entitled to student rates the participant must present a student card (or equivalent document) valid on July 31, 2011.
Student registrations must be accompanied by proof of full-time student
status (in form of scanned copy of a student ID card or equivalent document) and send by e-mail to ltc@amu.edu.pl. The e-mail
subject field must have the following format:
The conference fee covers:
|
|
Conference fee for accompanying persons is
50 EUR. The fee covers participation in non-scientific program
(banquet,session coffee breaks).
|
|
|
|
By credit card (recommended):
The completed and signed transfer information form is to be send (obligatorily) by fax to: +48 61 8279701 (Fundacja Uniwersytetu im. Adama Mickiewicza w Poznaniu) Important: if payment by bank transfer, all transfer fees (for both the transferring and the receiving banks) must be covered by the participant. Important: make sure you have included the name of the conference and your family name as part of the payment reference. |
|
|
|
Name: "Addressing the Gaps in Language Resources and Technologies"
The previous joint LTC-FLaReNet workshop on "Getting Less-Resourced Languages on-Board!" (LTC 2009) aimed at drawing a picture of the Language Resources (LR) and Language Technologies (LT) availability and quality, especially for the less-resourced languages. Following its success, this second workshop aims at adding the novel topics of gap identification and their possible filling. The workshop will draw on the inventories of all language technologies and resources that are presently being carried out, such as the ones conducted by FlaReNet, ELRA or META-NET (e.g. LRE Map, Program Surveys, Language Matrixes, Language Gaps, META-SHARE infrastructure). These are now available and help better understand the current landscape and work out the possible solutions, for each individual language and technology. The idea is to discuss availability, quality, maturity, sustainability, and gaps of the LR and LT for a number of languages and technologies. The importance of this confrontation and analysis will be reflected by the way conclusions will be endorsed by the participants. Topics:
Program (general framework):The workshop will comprise presentations (including keynote talks) and a panel session, including an EC representative . The details of the program is in preparation and will be published soon at this site. Co-Chairs: Khalid Choukri (ELRA, ELDA, France), Joseph Mariani (LIMSI-CNRS, IMMI, France), Zygmunt Vetulani (Adam Mickiewicz University, Poland) LRL Workshop Program Committee :
Paper submission: format and templates as for the general LTC, see the Paper Submission Section , above. Papers should be submitted using EasyChair exactly as for the general LTC but copies should also be send to the co-chairs of the Workshop, i.e. to choukri@elda.org, Joseph.Mariani@limsi.fr and vetulani@amu.edu.pl. Please also put "LRL'11 submission" as Subject of your mail and "LRL" as a key word (both in the EasyChair form and in the paper itself). More LRL participation details : cf. the general program (the access to the program of both the main conference and the workshop (as well as the social program) is the same for all LTC/LRL participants) |
|
|
|
Demos. The authors of submitted papers are invited to present demos of operational systems or language resources. However, as presentation possiblities are limited, a pre-registration before November 18 is required. Prority will be given to the first registered. Invited lecture and tutorial. An invited lecture on Extracting, Representing, and Reasoning about Time and Space in Texts and Discourse will be given by Gerard Ligozat (France) on November 27, afternoon. This lecture will then be continued during the week after the conference in form of a tutorial, free for all registered conference attenders. Participation in the tutorial will require separate refistration (details soon). Poster forum. Although all accepted papers will be presented by the authors in the traditional, standard way (oral presentation + discussion), the organizers will offer to the authors an additional opportunity to present (mini) posters containing the abstract and the key ideas of the paper (or related to the paper). Posters will be presented by the organizers during the LTC in the conference area. No extra fee will be charged for this form of presentation. The poster size will be A1, horizontal. In order to have your poster presented you are supposed to register it by November 18, 2011 by an e-mail send to ltc@amu.edu.pl with "LTC-poster" in the subject field.. (Notice. The Poster forum should not be confused with traditional poster sessions. In particular, there will be no limited presentation time and the posters do not have to be accompanied by the authors) A book exhibition is intended Also, registered participants are invited to bring hard copies of their papers and books. We plan to make special presentations of the achievements of the conference participants, irrespective of whether they are directly related to the conference topic. |
|
|
|
LTC 2011 will be located in the: Collegium Iuridicum Novum, Al. Niepodległości 53 and in the Hotel Polonez, Al. Niepodległości 36, Poznań (oposite).
| ||
|
|
|
Gala Dinner will be located in the: Collegium Maius, Fredry 10, Poznań. |
|
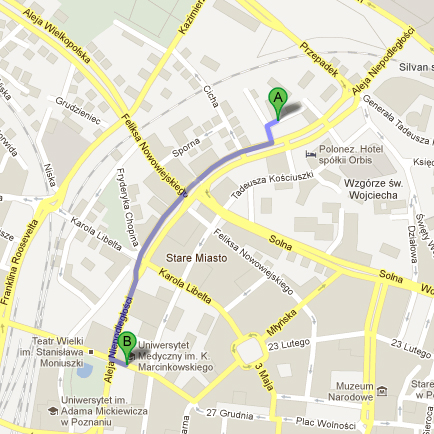
|
A - Collegium Iuridicum Novum B - Collegium Maius (Gala Dinner) Bus lines: 68, 71 (to the "Zamek" stop) |
|
|
|
As at the 2nd, 3rd and 4th Language and Technology Conferences (2005, 2007, 2009) special awards will be granted to the best student papers. The regular or PhD students (on the date of paper submission) are concerned. Co-authored papers will be considered provided that the students' contributions exceeds 60% and that the main author(s) is (are) student(s)(this fact must be documented by a written declaration signed by all co-authors). |
|
In 2005 the Jury, composed of the Program Committee members participating in the conference, awarded this distinction to: Ronny Melz (University of Leipzig), Hartwig Holzapfel (University of Karlsruhe), Marcin Woliński (IPI PAN, Warsaw) (picture at LTC 2011). |  |
| In 2007 the award for the best student paper was granted to Darja Fišer (University of Ljubljana). |  |
| In 2009 two awards were granted: to Mahmoud EL-Haj (University of Essex, UK) (left) and Alexander Pak (LIMSI-CNRS, Orsay, France) (right). |  |
| In 2011 the Jury decided to award three student contributions: Narayan Choudhary (Jawaharlal Nehru University, New Delhi, India)(left), Moses Ekpenyong (University of Uyo, Nigeria)(middle) and Marek Kubis (Adam Mickiewicz University in Poznań, Poland) (right). |  |
 |
 |
|
|
|
Participants from some non-EC countries may need visas to enter the Polish territory. Visa delivery is exclusively in competence of the Visa Authorities of the Schengen Convention countries. If you have any doubts, we recommend you to check your situation with the nearest Polish Consulate in your residence country. If you are author (co-author) of an accepted paper, we can confirm - if necessary - that we expect your presence at the conference for paper presentation. Upon request, we may also write a confirmation letter (in Polish) directly to the Polish Consulate indicated by you. To do this we will need a request letter (e-mail) from you in which you will provide us with the address of the Consulate you wish us to contact. To get information about countries whose citizens are not required to have a visa when entering Poland and to find important telephone numbers you may also visit the web site of the Polish Ministry of Foreign Affairs http://www.msz.gov.pl/index.php?document=2 (see Consular Information http://www.msz.gov.pl/Consular,Information,2345.html). |
|
|
|
This site is in progress. Further important practical information will be published shortly. Please consult this site again from time to time. |
|
|
|
There are several large scale events in Poznań at the LTC 2011 time (November 25-27, 2011). Therefore, we strongly recommend you to make the hotel reservation in advance. There are several standard possibilities to book via Internet. Also, a special offer for Conference participants has been prepared by the travel agency Zimny http://www.zimny.pl (zimny@zimny.pl). Please notice that the conference is located in Collegium Iuriducum Novum and in the Polonez Hotel Orbis (face to Collegium Iuridicum). If you prefer to stay in the Polonez Hotel you may make your reservation directly through the Hotel Polonez reservation service (reception). In that case please do remember that this hotel offers special rates to the LTC guests (mail to rez.polonez@orbis.pl putting LTC in the "subject" fiels or call them directly to +48 61 864 71 in order to benefit from this offer; the reservation link from this page is for information only /it does not offer the LTC discount/). |
|
|
 |
|
 |
|
|
|
The timetable (by tram or bus line) can be viewed at http://www.ztm.poznan.pl/komunikacja/rozklad/. (After choosing the line, one has to choose the proper bus or tram stop in the right direction.) Tickets fares are available at: http://ztm.poznan.pl/fares-tickets/fares-new/ An interactive transportation map is available at "Jak dojazde" website and provides also estimation of ticket cost for the given route. Aprox. bus travel duration to the Polonez hotel from (except rush hours):
You can buy tickets in one of the newspaper stands near bus stops. TAXI in Poznań:
Aprox. taxi travel cost to the Polonez hotel from:
|
|
|
|
Official promotional website of the Republic of Poland You could find there information about:
|

 LTC Registation at Collegium Iuridicum Novum
LTC Registation at Collegium Iuridicum Novum Hotel
Hotel