|
Day 1, Saturday, December 7, 2013
|
|
Collegium Maius
|
|
9:30 - 11:10
|
Registration / Welcome Coffee
|
|
11:10 - 11:40
|
Opening Ceremony
|
|
11:40 - 12:40
|
Keynote lecture by Wolfgang Wahlster, "The Next Generation of Multimodal Human-Environment Interfaces to Cyber-Physical Systems"
|
|
12:40 - 14:10
|
Lunch break
|
|
14:10 - 15:00
|
In memoriam of Leonard Bolc
|
|
15:00 - 15:20
|
Zygmunt Vetulani, Marek Kubis, Jacek Marciniak, Tomasz Obrębski, Bartłomiej Kochanowski, Grzegorz Taberski, "Language Technology at the Department of Computer Linguistics and AI (AMU)"
|
|
15:20 - 16:20
|
LTC Panel Discussion
|
|
Collegium Minus
|
|
16:20 - 17:00
|
Transfer (walking) and Coffee in Collegium Minus
|
|
17:00 - 18:20
|
TAN 1
|
MT 1
|
IR/IE 1
|
|
18:25 - 19:45
|
LRT 1
|
SEM
|
SPEECH 1
|
|
19:45 - 20:30
|
Welcome at Collegium Minus
|
|
Day 2, Sunday, December 8, 2013
|
|
Hotel Mercure - Conference Area
|
|
8:45 - 9:30
|
Girish Nath Jha, “Language Technology in India: Empowering millions”
|
|
9:30 - 9:45
|
Coffee break
|
Demo Session
|
|
9:45 - 11:05
|
LRT 2
|
OWN
|
SPEECH 2
|
|
11:05 - 12:45
|
LRT 3
|
PAR 1
|
IR/IE 2
|
|
12:45 - 14:30
|
Lunch offered by the City of Poznań
|
|
14:30 - 16:00
|
LRL Special Track (coffee break incl.)
"Less Resourced Languages, new technologies, new challenges and opportunities"
Co-chairs: Claudia Soria, Khalid Choukri, Joseph Mariani, Zygmunt Vetulani
|
SAIBS Special Track (coffee break incl.)
Social and Algorithmic Issues in Business Support "Knowledge Hidden in Text"
Co-chairs: Adam Wojciechowski, Alok Mishra
|
|
16:00 - 16:30
|
|
16:30 - 19:30
|
|
20:30 - 00:00
|
Conference banquet
|
Notice. The lecture of Girish Nath Jha will be continued - free for LTC participants - just after LTC at the Faculty of Mathematics and Computer Science, Umultowska Street (ul.) 87 (Kampus Morasko)
1) "Computer processing and natural language engineering of Indian languages. Case study of Sanskrit (part 1)", on December 10, 12:00-13:30
2) "Computer processing and natural language engineering of Indian Languages. Case study of Sanskrit (part 2)", on December 11, 8:15-9:45.
|
Notice. The lectures of Dafydd Gibbon will be continued on December 10 and December 11 - free for LTC participants:
1) "Data mining with annotated speech corpora", time and place to be announced. December 10, 9:00, Al. Niepodległości 4, Collegium Novum, room 601A.
2) "Complexity in language", on December 11, time and place to be announced.
moved to December 10
|
| Day 2: December 8, 2013 |
| DEMO Session |
| 9:30 - 13:05 |
| 3 |
Evaluating wordnets using query languages | Marek Kubis |
| 47 |
Demo of the corpus of computer-mediated communication in Hindi (CO3H) | Ritesh Kumar |
| 117 |
Demo of the CASMACAT post-editing workbench - Prototype-II: A research tool to investigate human translation processes for Advanced Computer Aided Translation | Mercedes García Martínez, Michael Carl and Bartolomé Mesa-Lao |
| 119 |
Syntactic Analyser for Quechua Language | Waldir Edison Farfan Caro, Jose Martin Lozano Aparicio and Juan Cruz |
| 120 |
SPPAS - DEMO | Brigitte Bigi |
| 121 |
OpeNER demo: Open Polarity Enhanced Named Entity Recognition | Aitor García-Pablos, Montse Cuadros and German Rigau |
| 122 |
Jasnopis: a new application for measuring readability of Polish texts | Włodzimierz Gruszczyński, Bartosz Broda, Bartłomiej Nitoń and Maciej Ogrodniczuk |
| 123 |
Lexus, an online encyclopedic lexicon tool | Shakila Shayan, Andre Moreira, Alexander Koenig, Sebastian Drude and Menzo Windhouwer |
| 124 |
A demo of ontology-based event extraction for the Polish and English languages | Jakub Dutkiewicz and Czesław Jedrzejek |
| 125 |
PlWordNet 2.1: DEMO | Marek Maziarz, Maciej Piasecki, Ewa Rudnicka and Stanisław Szpakowicz |
| 126 |
KorAP: the new corpus analysis platform at IDS Mannheim | Piotr Bański, Joachim Bingel, Nils Diewald, Elena Frick, Michael Hanl, Marc Kupietz, Piotr Pęzik, Carsten Schnober and Andreas Witt |
| 127 |
CorpusWiki: an online, language independent POS tag corpus builder (LRL) | Maarten Janssen |
| 128 |
Collocations in PolNet 2.0. New release of "PolNet - Polish Wordnet" | Zygmunt Vetulani, Marek Kubis and Bartłomiej Kochanowski |
| 130 |
IMAGACT. A Multilingual Ontology of Action based on visual representations | Massimo Moneglia |
| 131 |
Tour-pedia: a web application for the analysis and visualization of opinions for tourism domain | Andrea Marchetti, Maurizio Tesconi, Stefano Abbate, Angelica Lo Duca, Andrea D'Errico, Francesca Frontini and Monica Monachini |
| Session SPEECH 3: Contributions to Speech Processing |
| 14:15 - 15:55 |
| 29 |
Exploring temporal context in diachronic text documents for automatic OOV proper name retrieval | Imane Nkairi, Irina Illina, Georges Linares and Dominique Fohr |
| 49 |
Correcting Diacritics in the Slovak Texts Using Hidden Markov Model | Daniel Hladek, Ján Staš and Jozef Juhár |
| 52 |
Efficient constrained parametrization of GMM with class-based mixture weights for Automatic Speech Recognition | Arseniy Gorin and Denis Jouvet |
| 67 |
Recent Advances in the Slovak Dictation System for Judicial Domain | Milan Rusko, Jozef Juhar, Marian Trnka, Jan Stas, Sakhia Darjaa, Daniel Hladek, Robert Sabo, Matus Pleva, Marian Ritomsky and Stanislav Ondas |
| 92 |
An Automated Method for Creating New Synthetic Voices from Audiobooks | Aimilios Chalamandaris, Pirros Tsiakoulis, Sotiris Karabetsos and Spyros Raptis |
WARNING. This is not the final program. It may be subject of modifications. Please check the program table carefully and report us any bugs and errors. If you do not find your name and/or paper that means one of the following: your final paper was not accepted despite the initial conditional acceptance note, you didn't pay the due conference fee or you didn't register correctly. In such a case please do contact us immediately.
|
Non-student participants:
- Regular registration fee (payment before November 10, 2013): 190EURO
- Late registration fee (payment after November 9, 2013): 240 EURO
Student participants:
- Regular registration fee (payment before November 10, 2013): 120 EURO
- Late registration fee (payment after November 9, 2013): 160 EURO
To be entitled to student rates the participant must present a student
card (or equivalent document) valid on July 31, 2013.
Student registrations must be accompanied by proof of full-time student
status (in form of scanned copy of a student ID card or equivalent document) and send by e-mail to ltc13@amu.edu.pl. The e-mail
subject field must have the following format:
LTC-11-student-ID-card-'Name_of_participant'
(e.g. LTC-11-student-ID-card-Vetulani)
The conference fee covers:
- participation in the scientific program /including presentation of one paper/*)
- conference materials
- proceedings on CD and paper
- social events (banquet,...)
- coffee breaks
|
|
Conference fee for an accompanying persons is
50 EUR. The fee covers participation in non-scientific program
(banquet,session coffee breaks).
The fee for one extra page (max. 2 allowed) will be charged 20 Euro.
*) In case of multiple submission the extra fee of 120 Euro for one additional paper (not covered by the conference fee paid by a co-author) is to be paid.
|
|
By credit card (recommended):
Please do follow the following 6-step procedure:
- Download the form: [credit card form DOC] or [credit card form PDF]
- Print the form
- Complete the form
- Sign the form
- Send a copy of the signed form (pdf) by e-mail to "ltc13-payment@amu.edu.pl" (the "subject" field of your mail must have the following format "LTC13-CCForm-'your_family_name'"
- Send the same copy by fax to: +48 61 8295315
By bank transfer to the account:
| Name: |
Fundacja Uniwersytetu im. Adama Mickiewicza w
Poznaniu
ul. Rubież 46
PL 61-612 Poznań |
| Account (if payment in EURO): |
PL80 1750 1019 0000 0000 0655 1726 |
| Account (if payment in PLN): |
27 1750 1019 0000 0000 0550 6147 |
| Bank: |
Raiffeisen Bank Polska S.A. |
| SWIFT: |
RCBWPLPW |
You may download transfer information forms from: [bank transfer form DOC] or
[bank transfer form
PDF]
The completed and signed transfer information form is to be send (obligatorily)
by e-mail (pdf, attachment) to "ltc13-payment@amu.edu.pl" (the "subject" field of your mail must have the following format "LTC13-BTForm-'your_family_name'". Send the same copy by fax to: +48 61 8295315.
Important: if payment by bank transfer, all
transfer fees (for both the transferring and the receiving banks) must be paid by the participant.
Important: make sure you have included the name of the
conference and your family name as part of the payment
reference.
|
The 3rd LRL Workshop (A Joint LTC-ELRA-FLaReNet-META_NET Workshop on Less-Resourced Languages):
"Less Resourced Languages, new technologies, new challenges and opportunities"
|
|
Date: 8.12.2013, half-day (afternoon)
LTC Workshop paper submission deadline : 22.09.2013 October 6, 2013.
Theme:
Many less resourced languages (LRL) that are thriving to get a place in the digital space and that could profit of the new opportunities offered by the Internet and digital devices will seriously face digital extinction if they are not supported by Language Technologies. Language Technologies (LTs, i.e. spelling and grammar checkers, electronic dictionaries, localized interfaces, voice dictations, audio transcriptions and subtitling, as well as multimedia/multimodal search engines, language translators or information extraction tools) are essential instruments to secure usability of less resourced languages within the digital world, thus ensuring those languages equal opportunities and raising their profile in the eyes of natives but also non-natives from the younger, digitally-oriented generation. However, there are many challenges to be faced to equip less resourced languages with LTs (from basic to advanced): a substantial delay in development of basic technologies, a lack of cooperation among languages communities, a chronic shortage of funding (in particular for minority languages not officially recognized, yet often the most vital ones over the Internet) and the limited economic value placed over LTs for minority languages by the market rules. At this critical time, this workshop seeks to continue the debate as to what new technologies have to offer less resourced languages, and how the research community might seek to overcome the challenges and exploit the opportunities.
Topics:
- Experiences in the development of digital applications for LRLs
- LRLs in educational and entertainment applications
- LRTs for securing access and inclusion to speakers of LRLs
- Development of LRs through crowdsourcing
- Youth-oriented applications for revitalisation of LRLs
- Experiences/models of cooperation for development of LRTs for LRLs
- Business models
- Gaps in availability of LRTs for LRLs
- LR&Ts as a booster for the adoption of LRL within the digital world
- Lessons learnt from major recent infrastructure initiatives
- Infrastructures for making available LR and LT in all languages, and especially in the less-resourced ones
- Assessing Availability, Quality, Maturity and Sustainability of LT and LR, comparing the LRLs and the major ones
- Requirements for the production, validation and distribution of LR for less-resourced languages
- ...
Program (general framework): The workshop will comprise presentations (including keynote talks) and a panel session, including an EC representative . The details of the program is in preparation and will be published soon at this site.
Co-Chairs:
|
Claudia Soria (CNR-ILC, Italy)
|
Khalid Choukri (ELRA,ELDA, France)
|
Joseph Mariani (LIMSI-CNRS & IMMI, France)
|
Zygmunt Vetulani (Adam Mickiewicz University, Poland)
|
|
LRL Workshop Program Committee:
| Delphine Bernhard (LILPA, Strasbourg University, France) |
| Nicoletta Calzolari (CNR-ILC, Italy) |
| Khalid Choukri (ELRA,ELDA, France) |
| Daffyd Gibbon (Univ. Bielefeld, Germany) |
| Marko Grobelnik (J. Stefan Institute, Slovenia) |
| Girish Nath Jha (Jawaharlal Nehru University, India) |
| Alfred Majewicz (UAM, Poland) |
| Joseph Mariani (LIMSI-CNRS & IMMI, France) |
| Asunción Moreno (UPC, Spain) |
| Stellios Piperidis(ILSP, Greece) |
| Gabor Proszeky (Morphologic, Hungary) |
| Georg Rehm (DFKI, Germany) |
| Kepa Sarasola Gabiola (Univ. del Pas Vasco, Spain) |
| Kevin Scannell (St. Louis University, USA) |
| Claudia Soria (CNR-ILC, Italy) |
| Virach Sornlertlamvanich (NECTEC, Thailand) |
| Marko Tadić (University of Zagreb, Faculty of Humanities and Social Sciences, Croatia) |
| Marianne Vergez-Couret (Toulouse University, France) |
| Zygmunt Vetulani (UAM, Poland) |
| |
Sponsors: FLaReNet, ELRA, Meta_Net
Inscriptions: as for the general LTC (+ cc to workshop chairs)
Fees: LRL is an integral part of the LTC (with autonomous Program Committee). Fees and payment procedures are the same as for LTC and cover participation in the general program. Free for participants registered to the general LTC.
Paper submission: format and templates as for the general LTC (see the Paper Submission Section; above). Papers should be submitted using EasyChair exactly as for the general LTC but copies should also be sent to the co-chairs of the Workshop, i.e. to: Khalid Choukri, Joseph Mariani , Claudia Soria and Zygmunt Vetulani. Please also put "LRL'13 submission" as Subject of your mail and "LRL" as a key word (both in the EasyChair form and in the paper itself).
Presentation: publication in the LTC proceedings (paper + CD)
Reviewing: up to the workshop chairs + Program Committee
Program:
Session 1 (Chair: K. Choukri)
| 14h35 | Brigitte Bigi (LPL, France), A phonetization approach for the forced-alignment task |
| 14h55 | Lars Hellan and Dorothee Beermann (NTNU, Norway), A multilingual valence database for less resourced languages |
| 15h15 | Mohamed Elmahdy (Qatar University, Qatar), Mark Hasegawa-Johnson (University of Illinois, USA) and Eiman Mustafawi (Qatar University, Qatar), A transfer learning approach for under-resourced Arabic dialect speech recognition |
| 15h35 | Rajeev R R, Jisha P Jayan and Elizhabeth Sherly (Indian Institute of Information Technology and Management, India) Interlingua data structure for Malayalam |
| | | | | |
| 15h55 | Coffee break |
Session 2 (Chair: J. Mariani)
| 16h30 | Esha Banerjee, Shiv Kaushik, Pinkey Nainwani, Akanksha Bansal and Girish Nath Jha (Jawaharlal Nehru University, India), Linking and referencing multilingual corpora in Indian languages |
| 16h50 | Adrien Barbaresi (ENS Lyon, France), Challenges in web-corpus construction for low resource language in a post Bootcat world |
| 17h10 | Maarten Janssen (Universitat Pompeu Fabra, Spain), POS Tags and Less Resources Languages - The CorpusWiki Project |
| 17h30 | Marianne Vergez-Couret (Université de Toulouse, France), Tagging Occitan using French and Spanish Tree Tagger |
| 17h50 | Carlo Zoli and Silvia Randaccio (Smallcodes S.r.L., Italy), Smallcodes and LinMiTech: two faces of the same new business model for the development of LRTs for LRLs |
| 18h10 | Conclusions |
| | | | | |
| 18h15 | Panel session |
| | | | | |
| 19h15 | End |
More LRL participation details: cf. also the general program (the access to the program of both the main conference and the workshop (as well as the social program) is the same for all LTC/LRL participants).
|
2nd Workshop on Social and Algorithmic Issues in Business Support:
"Knowledge Hidden in Text"
|
|
Date: 9.12.2013, half-day
Theme:Searching for Knowledge and New Paradigms Hidden in Artifacts and Users’ Behaviour
Social trend observed in networking and business activity has several roots. First - it is a challenge for many of us to share our experience and productivity and become recognizable. Second - social or crowd creativity is a process of merging efforts and distributed resources in order to produce new quality and new products. Third - utilizing social energy and productivity may give beginning to new business paradigms. Among a variety of artifacts stored in computer networks text resources play an important role. Books, articles, reports, subtitles, comments, tables of data, e-mails, passwords and other textual feeds are easy to produce, easy to transfer, relatively easy to translate and very attractive to process and analyze. 2nd SAIBS is a place where we want to discuss methods of knowledge discovery in text, its visualization and commercialization.
An important contribution of social power is software developed and hosted by volunteers and distributed on word-of-mouth recommendation. By the way... isn't nowadays word-of-mouth derived from mining textual and multimedia content delivered via the Internet? During the workshop session we want to face social contribution to business processes taking into account possible benefits and risk factors. How far can business relay on social input? What are the limits or what are the areas where introducing crowdsourced parts may increase overall risk value to unacceptable level? What are social benefits gained by mining and aggregating knowledge derived from analysis social artifacts presented in text or other forms in global computer network.
Algorithmic trading (algo trading) practiced on stock markets and Forex trading platforms arises as a new challenge for algorithm designers. This field of knowledge and practice grown from human-eye analysis of text tables collecting series of prices is a good example how far computer algorithms can outperform humans in precision, speed and accuracy. During 2nd SAIBS we would like to face the phenomenon of social trading, compare models of passive income from trading systems based on algorithmic and social recommendation and discuss algo-trading boundaries. Should algorithmic trading become a part of computing science curricula? Finally we are also interested in research works which analyze crowd behaviour collected in text tables or visualized in form of charts.
Topics:
- Translation issues and multi-language data feeds
- Recommender systems based on textual content and comments analysis
- Mining text artifacts to feed recommender systems
- Visualization of text and digital data
- Social and language issues in software specification, design and production
- New face of interactive social games based on text instructions and wordplay
- Cultural and social issues in global software development
- Social sharing and exchange systems
- Crowdsourcing and crowdfounding
- Automatic trading systems
- Optimization algorithms in trade support
- Experimental discovery of market behaviour
- Business models based on mobile applications
- Knowledge commercialization
- Business process improvement
- ...
Co-Chairs:
|
Adam Wojciechowski (Poznan University of Technology, Poland)
|
Alok Mishra (Atilim University, Turkey)
|
|
SAIBS Workshop Program Committee:
| Wojciech Complak (Poznan University of Technology, Poland) |
| Arianna D'Ulizia (National Research Council, Rome, Italy) |
| Fernando Ferri (IRPPS, National Research Council, Rome, Italy) |
| Patrick Hamilton (University of the South Pacific, Fiji) |
| Alok Mishra (Atilim University, Turkey) |
| Miroslaw Ochodek (Poznan University of Technology, Poland) |
| Rory O'Connor (Dublin City University, Ireland) |
| Robert Susmaga (Poznan University of Technology, Poland) |
| Zygmunt Vetulani (Adam Mickiewicz University, Poland) |
Agnieszka Wegrzyn (University of Zielona Gora, Poland) |
| Adam Wojciechowski (Poznan University of Technology, Poland) |
| |
Inscriptions: as for the general LTC (+ cc to workshop chairs)
Fees: 2nd SAIBS Workshop is an integral part of the 6th Language and Technology Conference (with autonomous Program Committee). Fees and payment procedures are the same as for LTC and cover participation in the general program. Free for participants registered to the general LTC. Single registration covers only one paper presentation.
Publication
All papers accepted for SAIBS 2013 will be published in the LTC proceedings (printed hard copy, with ISBN number +CD). A post-conference volume with extended versions of selected papers is planned. As this was the case for the previous three LTC conferences, we intend to publish them in the Springer series Lecture Notes in Artificial Intelligence.
Moreover, authors of the best SAIBS 2013 papers will be invited to submit extended versions of their works to three international scientific journals:
- Applied Mathematics and Computer Science
- Control and Cybernetics
- Foundations of Computing and Decision Sciences
In order to qualify for the journal, the paper must be presented at SAIBS 2013 by one of its authors. Publication of selected papers in the journal will be subject to the second round of reviews (to verify if the paper satisfies the journal requirements, including 30% of new content when compared to the version from the LTC proceedings).
Paper submission: format and templates as for the general LTC (see the Paper Submission Section; above). Papers should be submitted using EasyChair exactly as for the general LTC but copies should also be sent to saibs@cs.put.poznan.pl. Please also put "SAIBS'13 submission" as Subject of your mail and "SAIBS" as a key word (both in the EasyChair form and in the paper itself).
Please notify, in order to keep review process fair, do not disclose the author(s) name(s) in any manner within the submitted paper.
Important dates:
- October 10, 2013, Submission of papers
- October 25, 2013, Notification of acceptance
November 2November 6, 2013, Camera-ready papersNovember 7November 9, 2013, Authors' payment and registration- December 7-9, LTC
- December 9, SAIBS 2013
Please consider the above date as hard deadlines
Program (general framework): The details of the program is in preparation and will be published soon at this site.
Presentation: publication in the LTC proceedings (paper + CD)
Reviewing: up to the workshop chairs + Program Committee
More SAIBS participation details: cf. also the general program (the access to the program of both the main conference and the workshop (as well as the social program) is the same for all LTC/SAIBS participants).
If you have any questions or doubts related to SAIBS 2013 Workshop do not hesitate to contact us via
saibs@cs.put.poznan.pl.
|
|
EXHIBITIONS AND SPECIAL EVENTS
|
|
A call for exibitions and special events in preparation.
|
|
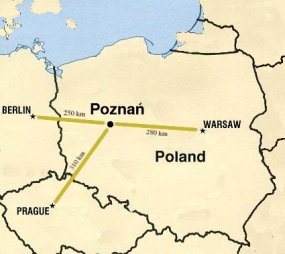
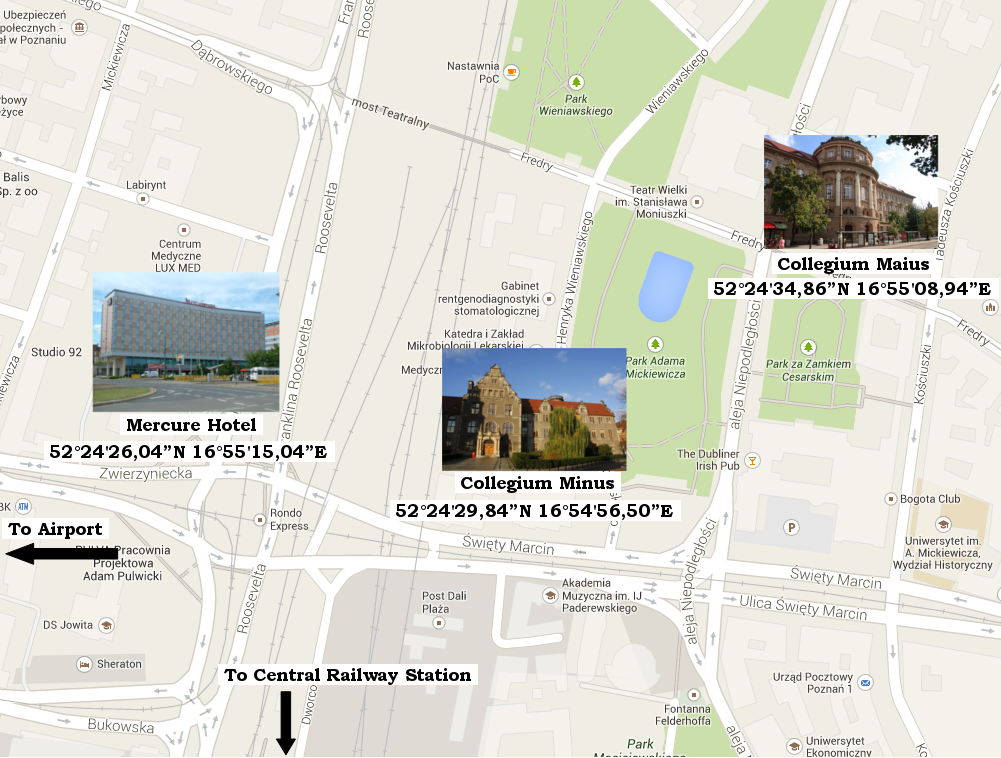
LTC 2013 will be located in Poznań.
The first day will be held in historical university buildings: morning registration, opening and the Leonard Bolc Session in Collegium Maius, Fredry Street 10 (ul. Fredry 10) (52°24'34,86”N 16°55'08,94”E); afternoon coffe brake and the rest of the day in Cllegium Minus (Rektor's Building) at Wieniawskiego Street 1 (52°24'29,84”N 16°54'56,50”E).
The conference will continue during the 2nd and 3rd day in the Mercure Hotel (300m walk from the 1st day location and 400m from the Poznań Central Railway Station ) at Roosevelta Street 20 (52°24'26,04”N 16°55'15,04”E)
|
|
|
|
AWARDS FOR THE BEST STUDENT PAPERS
|
|
As at the 2nd, 3rd, 4th and 5th Language and Technology Conferences (2005, 2007, 2009, 2011) special awards will be granted to the best student papers.
The regular or PhD students (on the date of paper submission) are concerned. Co-authored papers will be considered provided that the students'
contributions exceeds 60% and that the main author(s) is (are) student(s)(this fact must be documented by a written declaration signed by
all co-authors).
|
|
In 2005 the Jury, composed of the Program Committee members participating in the conference, awarded this distinction to:
Ronny Melz (University of Leipzig),
Hartwig Holzapfel (University of Karlsruhe),
Marcin Woliński (IPI PAN, Warsaw) (picture at LTC 2011).
|  |
|
In 2007 the award for the best student paper was granted to Darja Fišer (University of Ljubljana).
|  |
|
In 2009 two awards were granted: to Mahmoud EL-Haj (University of Essex, UK) (left) and Alexander Pak (LIMSI-CNRS, Orsay, France) (right).
|  |
|
In 2011 the Jury decided to award three student contributions:
Narayan Choudhary (Jawaharlal Nehru University, New Delhi, India)(left),
Moses Ekpenyong (University of Uyo, Nigeria)(middle) and
Marek Kubis
(Adam Mickiewicz University in Poznań, Poland) (right).
|
 |
 |
 |
|