Participants of former LTC events came from:

























































Participants of former LTC events came from:
|
Since 1995! 22nd Anniversary! |
|
|
|
as a Challenge for Computer Science and Linguistics |
|
|
Pioneer of logic programming in natural language processing LTC Program Committee member in 2005 who left us on May 12, 2017 |
|
|
|
Patronage:
|
|
|
|
|















|
 |
 |
|
Collegium Minus, Presidence |
|
|
|


|
|
|
|
|
|
|
|
Dear Colleagues, The 8th Language and Technology Conference (LTC 2017), a meeting organized by the Faculty of Mathematics and Computer Science of the Adam Mickiewicz University, Poznań, Poland and the Adam Mickiewicz University Foundation, will take place on November 17-19, 2017. Following the tradition of the past events, it is supported by ELRA, FlaReNet, and META-NET. Yes, we started 22 years ago! Our tradition goes back to the Language and Technology Awareness Days, a meeting organized in 1995 with the assistance of the European Commission (DG XIII). Among the key speakers were Antonio Zampolli (Italy), Dafydd Gibbon (Germany), Dan Tufiş (Romania), Orest Kossak (Ukraina). Today, we refer to this event as the first LTC. Ten years later, we decided to meet again, and since then the conference is being organized every two years as the “Language & Technology Conference: Human Language Technologies as a Challenge for Computer Science and Linguistics”. Since the very beginning (1995) the meetings of the LTC series continue to address Human Language Technologies (HLT) as a challenge for computer science, linguistics and related fields. Fostering language technologies and resources remains an important objective in our dynamically changing information-saturated world that motivate us to invite you for joining us at the LTC 2017 in Poznań.
Zygmunt Vetulani and Patrick Paroubek |
|
|
 |
|
Chris Cieri |
 |
|
Joseph van Genabith |
 (To see Verónica&Guitar click the picture)
(To see Verónica&Guitar click the picture)
|
|
Verónica Dahl |
 |
|
Jan Wielemaker |
|
|
 |
|
Alain Colmerauer (1941-2017), Pioneer of logic programming in natural language processing and LTC Program Committee member in 2005, left us on May 12, 2017
|
|
Call for Papers and Participation Alain Colmerauer Special Session on Logic Programming and NLP at the 8th Language and Technology Conference (LTC 2017), November 17-19, 2017, Poznań, Poland In memoriam Alain Colmerauer (1941-2017), Pioneer of logic programming in natural language processing, LTC Program Committee member in 2005 |
|
http://www.ltc.amu.edu.pl https://www.facebook.com/ltcpoznan In memory of Alain Colmerauer who left us on May 12, 2017, and to whom LTC 2017 is dedicated, we organize a special session, for which contributions that rely or extend his work, as well concerning himself are solicited. These contributions can be research as well as state of the art papers, mini-tutorials or demos. Besides papers on new results we will highly appreciate contributions reporting on author’s former results (already published or not), often remaining unknown to the large public, in particular those that directly refer to the work of Alain Colmeauer and/or his students. Also critical and comparative studies concerning logic programing versus other programming paradigms are welcome. We will consider: - papers, - posters, - demos, - and other forms. We plan a post-conference publication of peer reviewed full papers within 6 month after the conference (more details will be announced). Authors who wish to contribute to the Alain Colmerauer Session must submit an abstract according to the standard procedure indicated below and on this web page, and to inform the LTC 2017 organizers of their intention. We also intend an open panel discussion were we expect a wide participation. The Alain Colmerauer Session will be fully integrated with the LTC. This means that its program is accessible to all LTC participants, and similarly, the participants of the Session will have access to all LTC events. However, the session will have its own deadlines and publication policy. Please contact the organizers writing to vetulani@amu.edu.pl and stdizier@irit.fr (cc to k.r.apt@cwi.nl, mkubis@amu.edu.pl, and ltc17@amu.edu.pl). Zygmunt Vetulani, Patrick Saint-Dizier and Krzysztof Apt ORGANIZING COMMITTEE Zygmunt Vetulani (Poland), Patrick Saint-Dizier (France), Krzysztof Apt (The Netherlands and Poland) DATES/DEADLINES: * Deadline for submission of abstracts: October 26, 2017 * Acceptance/Rejection of abstracts: within one week after submission, but not later than November 1, 2017 * Participation fees for authors of accepted abstracts are to be payed no later than on November 1, 2017 * Colmerauer Session: during LTC, November 17-19, 2017 LANGUAGE The conference language is English. ABSTRACT SUBMISSION We accept abstracts in English only. The abstracts length should be of 3000 – 5000 characters (incl. spaces). Abstracts should contain the title, author(s) name(s) and affiliation(s), as well “Colmerauer Session” as a keyword. The abstracts should be submitted using the general LTC procedure (see section “Paper Submission” at www.ltc.amu.edu.pl). Abstract submission is obligatory to all active participants of the Colmerauer Session but does not exclude submission to the LTC – main conference. In that case following the general LTC submission procedure is mandatory. Important notice. The above mentioned forms of publication will not exclude of the publication in the post-conference book. POST-CONFERENCE PAPERS A post-conference volume with extended versions of selected papers will be published in Lecture Notes in Artificial Intelligence series (Springer Verlag). Papers will be selected based on reviewers’ reports among the best evaluated papers of general interest with new, innovative results. Preference will be given to papers providing significant content extension with respect to the paper presented at the conference. REGISTRATION Only electronic registration will be possible. Details will be published at www.ltc.amu.edu.pl. FEES As for all LTC events (see www.ltc.amu.edu.pl), for deadlines see DATES above. ABOUT LTC The 8th Language and Technology Conference (LTC 2017), a meeting organized by the Faculty of Mathematics and Computer Science of the Adam Mickiewicz University, Poznań, Poland and the Adam Mickiewicz University Foundation, will take place on November 17-19, 2017. Following the tradition of the past events, it is supported by ELRA, FlaReNet, and META-NET. Since the very beginning (1995) the meetings of the LTC series continue to address Human Language Technologies (HLT) as a challenge for computer science, linguistics and related fields. This year the conference will feature invited talks by Chris Cieri (Penn State University, USA), Verónica Dahl (Simon Fraser University, School of Computing Science, Burnaby B.C., Canada) , Joseph van Genabith (DFKI, Germany), and Jan Wielemaker (University of Amsterdam, Netherlands). For further information visit LTC website www.ltc.amu.edu.pl. CONTACT vetulani@amu.edu.pl (cc to mkubis@amu.edu.pl) |
|
|
|
The list of conference topics includes the following (the ordering is not significative):
This list is by no means closed and we are open to further proposals. Please do not hesitate to contact us in order to feed us with your suggestions and ideas of how to satisfy your expectations concerning the program. The Program Committee is also open to suggestions concerning accompanying events (workshops, exhibits, panels, etc). Suggestions, ideas and observations should be addressed directly to the LTC Co-Chairs by email (vetulani@amu.edu.pl or pap@limsi.fr) . |
|
|
|
On numerous requests and questions we are pleased to announce a special call for demos and posters to be presented during the LTC 2017 (November 17-19, 2017) at dedicated time slots.
The content of demos/posters must be strictly compatible with the thematic scope of the LTC (see above).
|
|
|
| Zygmunt Vetulani (Adam Mickiewicz University, Poznań, Poland) - chair |
| Patrick Paroubek(LIMSI-CNRS, Orsay, France) - chair |
| Victoria Arranz (ELRA, France) |
| Jolanta Bachan (Adam Mickiewicz University, Poznań, Poland) |
| Núria Bel (Universitat Pompeu Fabra, Barcelona, Spain) |
| Krzysztof Bogacki (Warsaw University, Poland) |
| Christian Boitet (IMAG, France) |
| Gerhard Budin (Univ. Vienna, Austria) |
| Nicoletta Calzolari (ILC/CNR, Italy) |
| Nick Campbell (Trinity College Dublin, Ireland) |
| Christopher Cieri (LDC, USA) |
| Khalid Choukri (ELRA, France) |
| Adam Dąbrowski (Poznań University of Technology, Poland) |
| Elżbieta Dura (University of Skovde, Sweden) |
| Katarzyna Dziubalska-Kołaczyk (Adam Mickiewicz University, Poznań, Poland) |
| Moses Ekpenyong (Uyo University, Nigeria) |
| Cedrick Fairon (University of Louvain, Belgium) |
| Christiane Fellbaum (Princeton University, USA) |
| Piotr Fuglewicz (TIP Sp. z o.o., Poland) |
| Maria Gavrilidou (ILSP, Greece) |
| Dafydd Gibbon (University of Bielefeld, Germany) |
| Marko Grobelnik (J. Stefan Institute, Slovenia) |
| Eva Hajičová (Charles University, Czech Republic) |
| Krzysztof Jassem (Adam Mickiewicz University, Poland) |
| Girish Nath Jha (Jawaharlal Nehru University, India) |
| Katarzyna Klessa (Adam Mickiewicz University, Poznań, Poland) |
| Cvetana Krstev (University of Belgrade, Serbia) |
| Eric Laporte (University Marne-la-Vallee, France) |
| Yves Lepage (Waseda University, Japan) |
| Gerard Ligozat (LIMSI/CNRS, France) |
| Natalia Loukachevitch (Research Computing Center of Moscow State University, Russia) |
| Wiesław Lubaszewski (AGH, Poland) |
| Bente Maegaard (Centre for Language Technology, Denmark) |
| Bernardo Magnini (ITC IRST, Italy) |
| Jacek Marciniak (Adam Mickiewicz University in Poznań, Poland) |
| Joseph Mariani(LIMSI-CNRS, Orsay, France) |
| Jacek Martinek (Poznań University of Technology, Poland) |
| Gayrat Matlatipov (Urgench State University,Uzbekistan) |
| Keith J. Miller (MITRE, USA) |
| Asunción Moreno (UPC, Spain) |
| Agnieszka Mykowiecka (IPI PAN, Poland) |
| Jan Odijk (Univ. Utrecht, The Netherlands) | Maciej Ogrodniczuk (IPI PAN, Poland) |
| Karel Pala (Masaryk University, Czech Republic) |
| Pavel S. Pankov (National Academy of Sciences, Kyrgyzstan) |
| Patrick Paroubek (LIMSI-CNRS, France) |
| Adam Pease (IPsoft, New York City, USA) |
| Maciej Piasecki (Wrocław University of Technology, Poland) |
| Stelios Piperidis (ILSP, Greece) |
| Gabor Proszeky (Morphologic, Hungary) |
| Georg Rehm (DFKI, Germany) |
| Michał Ptaszyński (University of Hokkaido, Japan) |
| Rafał Rzepka (University of Hokkaido, Japan) |
| Kepa Sarasola Gabiola (Univ. del Pas Vasco, Spain) |
| Frédérique Segond (Viseo Group, France) |
| Sanja Seljan (University of Zagreb, Croatia) |
| Zhongzhi Shi (Institute of Computing Technology / Chinese Academy of Sciences, China) |
| Janusz Taborek (Adam Mickiewicz University, Poznań, Poland) |
| Ryszard Tadeusiewicz (AGH, Poland) |
| Marko Tadić (University of Zagreb, Croatia) |
| Dan Tufiş (RCAI, Romania) |
| Hans Uszkoreit (DFKI, Germany) |
| Tamás Váradi (RIL, Hungary) |
| Andrejs Vasiljevs (Tilde, Latvia) |
| Cristina Vertan (Univ. Hamburg, Germany) |
| Dusko Vitas (University of Belgrade, Serbia) |
| Piek Vossen (VU University Amsterdam, Netherlands) |
| Jan Węglarz (Poznań University of Technology, Poland) |
| Bartosz Ziółko (AGH, Poland) |
| Mariusz Ziółko (AGH, Poland) |
| Richard Zuber (CNRS, France) |
| Andrzej Zydroń (XTM-INTL, UK) |
|
|
| Zygmunt Vetulani - chair / UAM (e-mail) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Jolanta Bachan / UAM | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Marek Kubis - secretary / UAM | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Jacek Marciniak / UAM | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Tomasz Obrębski / UAM | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Hanna Szafrańska / FUAM | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Marta Witkowska / UAM | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Mateusz Witkowski /UAM | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
The conference language is English. |
|
|
|
Acceptance will be based on the reviewers' assessments (anonymous
submission model /blind reviewing/). The accepted papers will be published in the conference
proceedings (hard copy, with ISBN number) and on CD-ROM. The abstracts
of the accepted contributions will also be made available via the
conference page (during its lifetime). Publication requires full
electronic registration and payment of the conference fee (full
registration) by at least one of the co-authors.
For the obvious reason that the conference fee must cover (in particular) the publication costs, the following rule is applied:
"One registration fee entitles publication of one paper.
A post-conference volume with extended versions of selected papers will be published in the Springer Verlag series Lecture Notes in Artificial Intelligence.
The LTC 2005 post conference selection appeared in form of Special Issue of Archives of Control Sciences (2005, Volume 15 nb. 3 and Volume 15 nb. 4) The LTC 2007 post-conference volume (revised, extended papers) appeared in the Springer Verlag series LNAI (vol. 5603). The LTC 2009 post-conference volume (revised, extended papers) appeared in the Springer Verlag series LNAI (vol. 6562). The LTC 2011 post-conference volume (revised, extended papers) appeared in the Springer Verlag series LNAI (vol. 8387). The LTC 2013 post-conference volume (revised, extended papers) appeared in the Springer Verlag series LNAI (vol. 9561). The LTC 2015 post-conference volume (revised, extended papers) is in preparation.
|
|
|
|
The conference accepts papers in English only. Papers (5 pages in the conference format) are due by September 25, 2017 (midnight, any time zone) and should not disclose the author(s) in any manner. In order to facilitate submission we have decided to reduce the formatting requirements as much as possible at this stage. Please, however, do observe the following:
The Word template (ELRA/LREC based format) is available here. The Latex template (ELRA/LREC based format) is available here. All submissions are to be made electronically via the LTC'17 web submission system (EasyChair). Acceptance/refusal notification will be sent by October 16, 2017. At the same time, the detailed guidelines for the final submission of accepted papers will be published on the conference web site. |
|
|
|
The deadline for final submissions is October 27, 2017.
Final papers should be sent by e-mail to ltc17@amu.edu.pl as an attachment and should conform to the following rules:
|
|
|
|
|
|
|
|
|
|
Non-student participants:
To be entitled to student rates the participant must present a student card (or equivalent document) valid on July 31, 2017.
Student registrations must be accompanied by proof of full-time student
status (in form of scanned copy of a student ID card or equivalent document) and send by e-mail to ltc17@amu.edu.pl. The e-mail
subject field must have the following format:
The conference fee covers:
|
|
Conference fee for an accompanying persons is
50 EUR. The fee covers participation in non-scientific program
(banquet,session coffee breaks).
|
|
|
|
8:00 - 10:30 Registration 11:00 - 11:15 Opening by the Adam Mickiewicz University Rector 11:15 - 11:40
Colette Colmerauer: about Alain Colmerauer's work PDF
11:40 - 12:20
Truth and Beauty in Computational Linguistics - Invited Talk by Verónica Dahl PDF
12:20 - 14:10 Lunch break 14:10 - 15:30 15:30 - 16:00 Coffee break 16:00 - 16:40 Addressing the Language Resource Gap through Alternative Incentives, Workforces and Workflows - Invited Talk by Chris Cieri PDF 16:45 - 18:25 8:20 - 9:40 9:40 - 10:40
POSTERS/DEMOS session & coffee 10:40 - 11:20
A Second Life for Prolog - Invited Talk by Jan Wielemaker PDF 11:25 - 12:25 12:30 - 13:30
Presentation by the LTC sponsor: The Amazon Development Center 13:30 - 15:15 Lunch break 15:15 - 15:55
The Impact of Neural Networks on Language Technologies a Case Study on Machine Translation - Invited Talk by Joseph van Genabith PDF 15:55 - 16:25 Coffee break 16:25 - 17:45 17:50 - 19:10 A Second Life for Prolog Tutorial (1) - by Jan Wielemaker 20:30 - 00:00 Conference Gala Dinner 08:00 - 10:00 Second Life for Prolog Tutorial (2) - by Jan Wielemaker 10:00 - 10:30 Coffee break 10:30 - 11:45 Presentation by the LTC sponsor: Samsung Poland R&D Institute PDF 11:45 - 12:45 Panel discussion 12:45 - 14:15 Lunch break 14:15 - 15:35 15:40 - 16:00 Closure session |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
• Affect Analysis (and its applications) • Cognitive aspects of decisions and opinions • Decisions and NLP • Ethics and NLP • Knowledge acquisition • Opinion Mining • Pragmatics of decision making • Preference models • Recommendation Systems • Sentiment Analysis • Social Informatics • Text mining techniques Program The access to the program of both the main conference and the workshops (as well as the social program) is the same for all LTC/EDO participants. Organizers • Michał Ptaszyński, ptaszynski@cs.kitami-it.ac.jp (Kitami Institute of Technology, Japan) • Rafał Rzepka, rzepka@ist.hokudai.ac.jp (Hokkaido University, Japan) (Hokkaido University, Japan) • Paweł Dybała, aweldybala1@gmail.com (Jagiellonian University, Poland) Program Committee • Alladin Ayesh, aayesh@dmu.ac.uk (De Montfort University, UK) • Karen Fort, karen.fort@paris-sorbonne.fr (Sorbonne, France) • Dai Hasegawa, daihasg@gmail.com (Aoyama Gakuin University, Japan) • Magdalena Igras-Cybulska, migras@agh.edu.pl (AGH, Poland) • Yasutomo Kimura, kimura@res.otaru-uc.ac.jp (Otaru University of Commerce, Japan) • Paweł Lubarski, Pawel.Lubarski@cs.put.poznan.pl (Poznań University of Technology, Poland) • Fumito Masui, f-masui@mail.kitami-it.ac.jp (Kitami Institute of Technology, Japan) • Mikołaj Morzy, mikolaj.morzy@put.poznan.pl (Poznań University of Technology, Poland) • Koji Murakami, koji.murakami@rakuten.com (Rakuten, USA) • Noriyuki Okumura, okumura@akashi.ac.jp (National Institute of Technology, Akashi College, Japan) • Michał B. Paradowski, michal.paradowski@uw.edu.pl (University of Warsaw) • Tyson Roberts, tyson@goldengate.net (Google, Japan) • Marcin Skowron, marcin.skowron@ofai.at (Johannes Kepler University, Austria) • Yuzu Uchida (Hokkai-gakuen University, Japan) • Zygmunt Vetulani (Adam Mickiewicz University, Poland) • Katarzyna Węgrzyn-Wolska (Efrei/Esigetel, France) • Adam Wierzbicki (Polish-Japanese Institute of Information Technology, Poland) • Bartosz Ziółko (AGH, Poland) |
|
Inscription procedure: as for the general LTC (+ cc to workshop chairs) Fees: The EDO Workshop is an integral part of the LTC (with autonomous Program Committee). Fees and payment procedures are the same as for LTC and cover participation in the general program. Free for participants registered to the general LTC. Single registration covers only one paper presentation (cf. the Publication Policy section). Papers:The EDO Workshop accepts papers in English only. Submitted texts should not disclose the author(s) in any manner. Format and templates are the same as for the general LTC (see the Paper Submission Section; above). Papers should be submitted using EasyChair exactly as for the general LTC but copies should also be sent to the EDO Workshop ) organizers i.e. to: Kenji Araki and Paweł Dybała. Please also put "EDO 2015 submission" as Subject of your mail and "EDO" as a key word (both in the EasyChair form and in the paper itself). Presentation: publication in the LTC proceedings (paper + CD) More about EDO 2017: cf. http://arakilab.media.eng.hokudai.ac.jp/LTC8/EDO2017/ABOUT.html (the access to the program of both the main conference and the workshop (as well as the social program) is the same for all LTC/EDO participants). |
|
|
|
The rapid growth of language technology has created a new challenge for many languages of the world today. While for some, this can take the shape of a positive competition among the stake holders, for others it can push them further down in the race towards endangerment and extinction. The LT-LRL Workshop is an attempt to bring together all stake holders, users, developers, researchers, language activists, policy makers on a single platform and discuss how resources, policies, standards could be developed for these languages so that they can develop technologies to enable themselves in the digital age. We will particularly welcome contributions addressing the following issues: 1) LRL: charting the field - what do we know about currently available LTs for LRLs? What is the current status of language technologies and use of LRLs in the digital and social media environments? How to draw a comprehensive and accurate picture and create a road map for future? Who are the actors to be involved? What is the experience of researchers and developers? 2) LRL: Resource development - how are the LRLs dealing with resource crunch, creation and related issues of standards, IDEs and platforms, funding, usability, sharing etc? What are the perceptions and roles of various stake holders including the governments, industry and language communities? What are the additional challenges posed by multilingual societies? What are the language preservation strategies for LRLs in the digital age? 3) LRL : technology development - challenges in the development of specific enabling technologies for LRLs at language, speech and multi-modal levels. How are these technologies used in areas such as communication, education, entertainment, health, administration. governance etc?
Fees: LRL is an integral part of the LTC (with autonomous Program Committee). Fees and payment procedures are the same for general LTC and worshop participants (cover participation in the general LTC program). Notice: the workshop is free for participants registered to the general LTC. Single registration covers only one paper presentation (general LTC or workshops) (cf. the Publication Policy section in case of more than one submitted paper).
Submition:
The papers accepted for LRL 2017 will be published in the LTC Proceedings (hard copy, with ISBN number) and on CD-ROM. After the Workshop, a selection of the best papers will be published together with best LTC papers in a dedicated volume in the Springer Series Lecture Notes in Artificial Intelligence. Reviewing and acceptance: on the ground of blind reviewing More LRL participation details: cf. also the general program (the access to the program of both the main conference and the workshop (as well as the social program) is the same for all LTC/LRL participants). |
|
|
|
PolEval Organizing Committee
Maciej Ogrodniczuk (Institute of Computer Science, Polish Academy of Sciences) Theme and Motivation PolEval is a SemEval-inspired evaluation campaign for natural language processing tools for Polish. Submitted tools compete against one another within certain tasks selected by organisers, using available data and are evaluated according to pre-established procedures. PolEval 2017-related papers will be presented at a special session during LTC 2017. Details can be found at the PolEval 2017 website.Task 1: POS Tagging There is an ongoing discussion whether the problem of part of speech tagging is already solved, at least for English, by reaching the tagging error rates similar or lower than the human inter-annotator agreement, which is ca. 97%. In the case of languages with rich morphology, such as Polish, there is however no doubt that the accuracies of around 91% delivered by taggers leave much to be desired and more work is needed to proclaim this task as solved. The aim of this proposed task is therefore to stimulate research in potentially new approaches to the problem of POS tagging of Polish, which will allow to close the gap between the tagging accuracy of systems available for English and languages with rich morphology. Registered systems compete in three settings:
Subtask (A): Morphosyntactic disambiguation and guessing:
Given a sequence
of segments, each with a set of possible morphosyntactic interpretations,
the goal of the task is to select the correct interpretation for each of the
segments and provide an interpretation for segments for which only 'ign'
interpretation has been given (segments unknown to the morphosyntactic
dictionary). Task 2: Sentiment analysis Sentiment analysis is a vital research area, approached at different levels: phrase-level (either in the context of opinion targets/aspects or phrases defined as syntactic sub-trees), sentence-level (related to the task of tweet-level analysis). The aim of this task is to promote research on this topic in the context of the Polish language, provide reference data sets to work and motivation for potentially new methods. The systems compete in one setting: Given a set of syntactic dependency trees, the goal of the task is to provide the correct sentiment for each sub-tree (phrase). Phrases correspond to sub-trees of dependency parse tree. The annotations assign sentiment values to whole phrases (and in some cases, sentences), regardless of their type. Important Dates
September 25, 2017: Deadline for submission of papers for review Presentation of results All accepted system descriptions, following the LTC 2017-compatible review process (in a special track and with a special deadline set to end of August) will be published in the conference proceedings provided the author registers to the conference under standard LTC conditions. Extended versions of best papers from each main track will be recommended for publication in the post-conference Springer's LNAI volume (subject to additional rounds of reviews). |
|
|
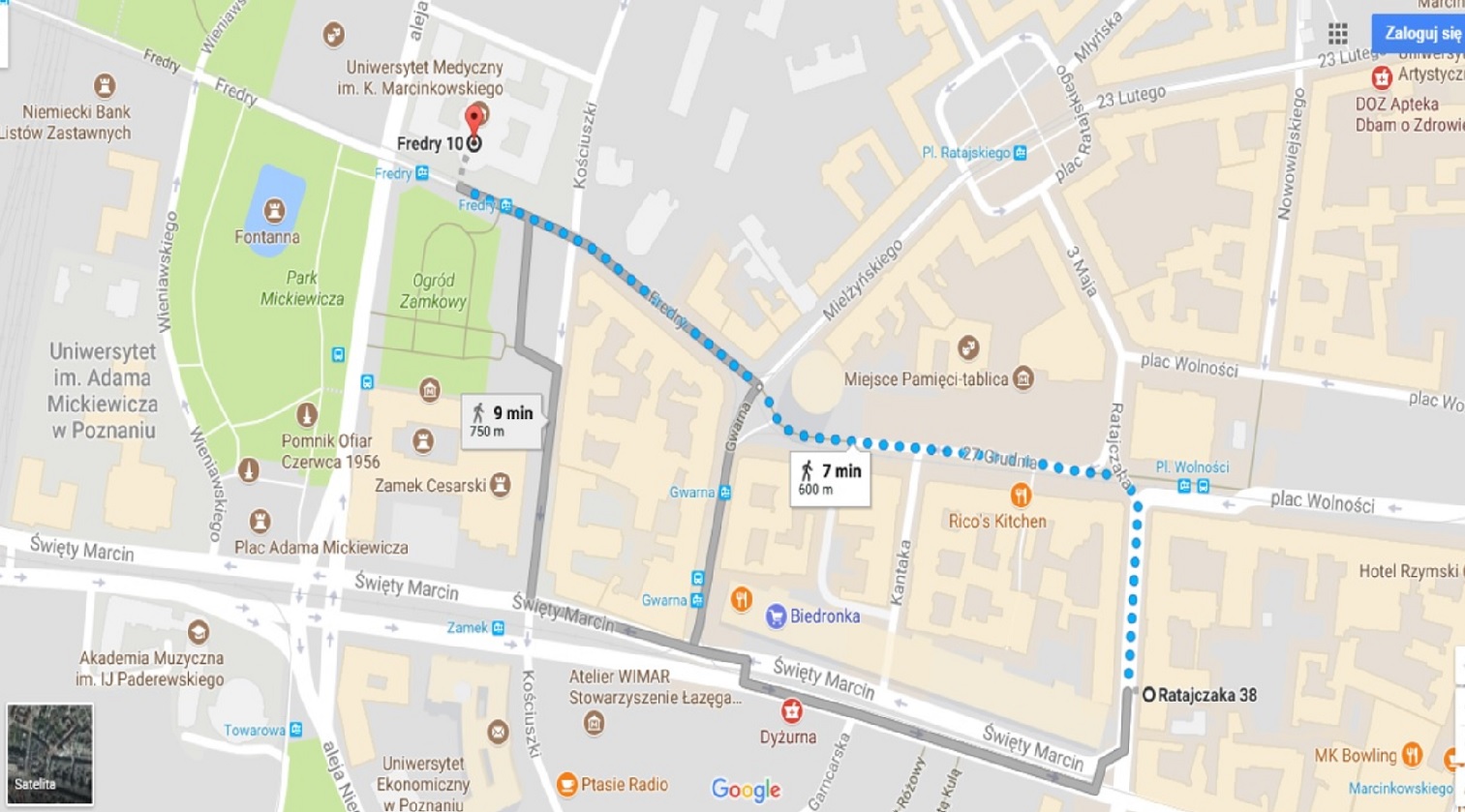
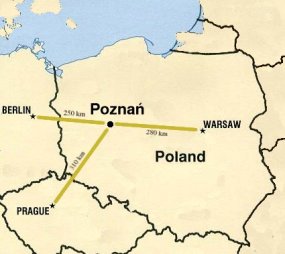
LTC 2017 is located in the Adam Mickiewicz University Library (Biblioteka Uniwersytecka), ul. Ratajczaka 38/40, 61-816 Poznań.
As at the 2nd, 3rd, 4th, 5th, 6th and 7th Language and Technology Conferences (2005, 2007, 2009, 2011, 2013,2015) special awards will be granted to the best student papers.
The regular or PhD students (on the date of paper submission) are concerned. Co-authored papers will be considered provided that the students'
contributions exceeds 60% and that the main author(s) is (are) student(s)(this fact must be documented by a written declaration signed by
all co-authors).
In 2005 the Jury, composed of the Program Committee members participating in the conference, awarded this distinction to:
Ronny Melz (University of Leipzig),
Hartwig Holzapfel (University of Karlsruhe),
Marcin Woliński (IPI PAN, Warsaw)
(picture at LTC 2011).
Notice. Pictures are clickable.
|
|
|
|
This site is in progress. Further important practical information will be published shortly. Please consult this site again from time to time. |
|
|
|
Students interested in joining our team of volunteers at the conference are kindly asked to send an email to obrebski@amu.edu.pl (cc: mkubis@amu.edu.pl). Please use LTC2017-Volunteer as a subject of your message. |
|
|
|
|
|
Travel to Poland - official information of the Ministry of Foreign Affaira of the Republic of Poland
|
|
|
| Address: | The 8th Language and Technology
Conference (LTC 2017) Adam Mickiewicz University Faculty of Mathematics and Computer Science Department of Computer Linguistics and Artificial Intelligence ul. Umultowska 87 PL 61-614 Poznań |
| E-mail: | ltc17@amu.edu.pl |
| WWW: | http://www.ltc.amu.edu.pl |
 |